Curating & Publishing Projects¶
Curation & Publication Guides¶
Below are step-by-step guides on how to create projects in the Data Depot, and curate and publish work/data across DesignSafe. We offer the following project types when publishing: Experimental, Simulation, Hybrid Simulation, Field Research, and Other. More information on Data Depot policies, project types, and curation/publication can be found at:
Experimental¶
1. Add a Project¶
You can start a project at the very beginning of its lifespan, upload and curate data incrementally, then publish sets of data at your convenience.
To add a new project, click + Add, then select New Project.

In the Add New Project window, fill in a project title and list the principal investigator (PI) and project members.

PIs and project members have the same level of access to the project, but the PI will be listed separately in the metadata. Additional PIs will be listed as Co-PIs.
You can edit all these fields later if you make any mistakes.
Once finished, click + Add Project and you will be taken to your new project in the My Projects tab.
2. Add an Experiment¶
To begin curation and add an experiment, click on the Curation Directory and select Experimental as your Project Type.

Go through the overview and fill out additional required fields in the Edit Project window, click Update Project, then click Add Experiments.
Adding an experiment involves filling out high level information about the files you will be publishing. Each experiment will receive its own DOI. Add multiple experiments if any of this information changes or you want multiple DOIs. Do not add another experiment if you are testing multiple models and this information stays the same. Instead, you can add multiple models to one experiment.

Fill out the required and optional fields using the advice given to create concise and understandable descriptions.
Also, assign authorship from a list of the project members and PIs. You can order the authors later when it is time to publish.
Click + Add Experiment when you are done and it will appear below in your inventory.
You can edit an experiment from the inventory.
3. Add Categories¶
Click Add Categories to begin.

Categories group files together based on a shared purpose in an experiment. Be sure and read the definitions of each category to understand what files belong to each.
Model Configuration Files describing the design and layout of what is being tested (some call this a specimen).
Sensor Information Files about the sensor instrumentation used in a model configuration to conduct one or more event.
Event Files from unique occurrences during which data are generated.
Analysis Tables, graphs, visualizations, Jupyter Notebooks, or other representations of the results.
Report Written accounts made to convey information about an entire project or experiment.
After filling out the fields, click + Add Category and it will appear below in your inventory. If you make any mistakes, expand the category and click Edit.
4. Relate Data¶
Click Relate Data to begin.

Relating Data allows you to relate categories to each other and to an experiment, which determines the layout and order of categories in your publication. You can reorder the categories if needed.
When published, this diagram will help others understand the structure of your experiment at a glance.
5. Assign Categories to Files¶

As you create categories, they will appear in a dropdown by each file. This allows you to group files in each category. Click Save to confirm the category.
If you categorize a folder, then all files within that folder will belong to the category of the folder.
A file can belong to one or more categories.
Click Remove if you make any mistakes.

6. Tag Files¶

After putting files in categories, dropdowns will appear to allow you to tag specific files.
The natural hazards community has contributed to creating these agreed upon terms.
These tags are optional, but recommended.
If you do not see a file tag that fits, you can select Other and write in your own.
7. Publication Preview¶

All of the curation work is done in the Curation Directory, while the Publication Preview lets you examine the layout of your publication to give you a peace of mind about how your work will appear to other researchers once published.

Look through the Publication Preview early and often to catch any mistakes. If you are working collaboratively with others, this is a good way to proofread changes they make.
8. Prepare to Publish¶
When you are satisfied with how your work is curated and wish to publish it, select Prepare to Publish in the Publication Preview.

There are 6 stages in the publication process:
Selection, Proofread Project, Proofread Experiment, Proofread Categories, Order Authors, and Licenses
In Selection, select which experiment you want to publish. You can only publish one at a time.
In Proofread Project, Experiment, & Categories, take time to proofread all the descriptions and metadata you have entered. You cannot make changes after publishing.
In Order Authors, order the authors of the experiment and preview how your citation will appear.
In Licenses, select one or more licenses that best fit your data.
Finally, click Request DOI & Publish and agree to the agreement to publish your work.
Simulation¶
1. Add a Project¶
You can start a project at the very beginning of its lifespan, upload and curate data incrementally, then publish sets of data at your convenience.
To add a new project, click + Add, then select New Project.
In the Add New Project window, fill in a project title and list the principal investigator (PI) and project members.
PIs and project members have the same level of access to the project, but the PI will be listed separately in the metadata. Additional PIs will be listed as Co-PIs.
You can edit all these fields later if you make any mistakes.
Once finished, click + Add Project and you will be taken to your new project in the My Projects tab.
2. Add a Simulation¶
To begin curation and add a simulation, click on the Curation Directory and select Simulation as your Project Type.

Go through the overview and fill out additional required fields in the Edit Project window, click Update Project, then click Add Simulations.
Adding a simulation involves filling out high level information about the files you will be publishing. Each simulation will receive its own DOI. Add multiple simulations if any of this information changes or you want multiple DOIs. Do not add another simulation if you are testing multiple models and this information stays the same. Instead, you can add multiple models to one simulation.

Fill out the required and optional fields using the advice given to create concise and understandable descriptions.
Also, assign authorship from a list of the project members and PIs. You can order the authors later when it is time to publish.
Click + Add Simulation when you are done and it will appear below in your inventory.
You can edit a simulation from the inventory.
3. Add Categories¶
Click Add Categories to begin.
Categories group files together based on a shared purpose in a simulation. Be sure and read the definitions of each category to understand what files belong to each.

Simulation Model Files and/or information describing the design, geometry, and/or code of a simulation.
Simulation Input Files containing the parameters of the simulation.
Simulation Output Files containing the results of a simulation.
Analysis Tables, graphs, visualizations, Jupyter Notebooks, or other representations of the results.
Report Written accounts made to convey information about an entire project or simulation.
After filling out the fields, click + Add Category and it will appear below in your inventory. If you make any mistakes, expand the category and click Edit.
4. Relate Data¶
Click Relate Data to begin.
Relating Data allows you to relate categories to each other and to an simulation, which determines the layout and order of categories in your publication. You can reorder the categories if needed.

When published, this diagram will help others understand the structure of your simulation at a glance.
5. Assign Categories to Files¶
As you create categories, they will appear in a dropdown by each file. This allows you to group files in each category. Click Save to confirm the category.

If you categorize a folder, then all files within that folder will belong to the category of the folder.
A file can belong to one or more categories.
Click Remove if you make any mistakes.
6. Tag Files¶
After putting files in categories, dropdowns will appear to allow you to tag specific files.

The natural hazards community has contributed to creating these agreed upon terms.
These tags are optional, but recommended.
If you do not see a file tag that fits, you can select Other and write in your own.
7. Publication Preview¶
All of the curation work is done in the Curation Directory, while the Publication Preview lets you examine the layout of your publication to give you a peace of mind about how your work will appear to other researchers once published.

Look through the Publication Preview early and often to catch any mistakes. If you are working collaboratively with others, this is a good way to proofread changes they make.

8. Prepare to Publish¶

When you are satisfied with how your work is curated and wish to publish it, select Prepare to Publish in the Publication Preview.

There are 6 stages in the publication process:
Selection, Proofread Project, Proofread Simulation, Proofread Categories, Order Authors, and Licenses
In Selection, select which simulation you want to publish. You can only publish one at a time.
In Proofread Project, Simulation, & Categories, take time to proofread all the descriptions and metadata you have entered. You cannot make changes after publishing.
In Order Authors, order the authors of the simulation and preview how your citation will appear.
In Licenses, select one or more licenses that best fit your data.
Finally, click Request DOI & Publish and agree to the agreement to publish your work.
Hybrid Simulation¶
Hybrid Simulation User Guide in progress.
Field Research¶
Field Research User Guide is in progress.
1. Add a Project¶
You can start a project at the very beginning of its lifespan, upload and curate data incrementally, then publish sets of data at your convenience.
To add a new project, click + Add, then select New Project.
In the Add New Project window, fill in a project title and list the principal investigator (PI) and project members.
PIs and project members have the same level of access to the project, but the PI will be listed separately in the metadata. Additional PIs will be listed as Co-PIs.
You can edit all these fields later.
Once finished, click + Add Project and you will be taken to your new project in the My Projects tab.
2. Add a Mission¶
To begin curation, click on the Curation Directory and select Field Research as your Project Type.
Please, read the overview, it has information that will clarify and guide you through the curation process.
Fill out required fields in the Edit Project window. Without this information your project will not be published. Click Update Project, then click Add Missions.


A mission is a group of data collections that are associated with a common goal or time. Some researchers may also refer to this as Time or Wave.
Adding a mission involves filling out high-level information (e.g. title, date, geolocation and description) about the files you will be publishing.
Each mission will receive a unique DOI. Add multiple missions if any of this high-level information changes or you want multiple DOIs. Do not add another mission if you are surveying the same location with different instruments and this information stays the same. Instead, you can add multiple collections to one mission.
Fill out the required and optional fields using the advice given to create concise and understandable descriptions. You can order the authors later when it is time to publish.
Click + Add Mission when you are done and it will appear below in your inventory.
You can edit a mission from the mission inventory.
3. Add Collections¶
Click Add Collections to begin.
Collections group files together based on a shared purpose in a mission. There are three different collection types in field research data model:
Research Planning Collection:
A group of files related to planning and logistics, study design and administration, design, Institutional Review Board (IRB) procedures, or permits.
Engineering/Geosciences Collection:
A group of related data and associated materials from the engineering/geosciences domain.
Social Sciences Collection:
A group of related data and associated materials from the social sciences domain.
When defining a collection, there are several information that are required to be filled for curation and publication purposes such as collection title, observation type, data of collection, data collector, collection site location, the instrument and a summarized description.
After filling out the fields, click + Add Collection and it will appear below in your collection inventory. If you make any mistakes, expand the category and click Edit.

4. Relate Data¶
Click Relate Data to begin.
Relating Data allows you to relate collections to missions, which determines the organization of your dataset. You can also establish the order of your collections.
When published, this diagram will help others understand the structure of your Field Research. Now you are ready to assign files to your collections.

5. Assign Collections to Files¶
As you create collections, they will appear in a dropdown next to each file. This allows you select collections for any file in your project and group them under each collection. Click Save to confirm the collection.
If you assigned a collection to a folder, then all files within that folder will belong to the collection of the folder.
A file can belong to one or more collections.
Click Remove if you make any mistakes.


6. Tag Files¶
After putting files in collections, dropdowns will appear to allow you to tag/describe unique files.
The natural hazards community has contributed to creating these agreed upon terms.
These tags are optional, but recommended.
If you do not see a file tag that fits, you can select Other and write in your own descriptive tag.

7. Publication Preview¶
All of the curation work is done in the Curation Directory. The Publication Preview lets you examine the layout of your publication so you can visualize/verify how your work will appear once published.
Look through the Publication Preview early and often to make changes or catch mistakes. If you are working collaboratively with others, this is a good way to proofread changes.


8. Prepare to Publish¶
When you are satisfied with how your work is curated and wish to publish it, select Prepare to Publish in the Publication Preview.
There are 6 stages in the publication process:
Selection, Proofread Project, Proofread Mission, Proofread Collections, Order Authors, and Licenses
In Selection, select which mission you want to publish. At this time, you can only publish one mission at a time.
In Proofread Project, Missions, & Collections, take time to read all the descriptions and metadata you have entered. You will not be able to make changes after publishing.
In Order Authors, order the authors of the mission and preview how your citation will appear.
In Licenses, select one or more licenses that best fit your data.
Please see the Data Publication Guidelines for more information.
Finally, click Request DOI & Publish and agree to the agreement to publish your work.

Other¶
1. Add a Project¶
To add a new project, click + Add, then select New Project.
In the Add New Project window, fill in a project title and list the principal investigator (PI) and project members.
PIs and project members have the same level of access to the project, but the PI will be listed separately in the metadata. Additional PIs will be listed as Co-PIs.
You can edit all these fields later if you make any mistakes.
Once finished, click + Add Project and you will be taken to your new project in the My Projects tab.
2. Begin Curation¶
To begin curating and tagging your files, click on the Curation Directory and select Other as your Project Type.

Fill out additional required fields in the Edit Project window, including a Data Type, then click Update Project and you will be brought to the Curation Directory.

3. Tag Files¶
Dropdowns will appear by each file to allow you to tag specific files.

These tags are optional, but recommended. The help other users understand your data and discover it in searches.
If you do not see a file tag that fits, you can select Other and write in your own.
4. Prepare to Publish¶
When you are satisfied with your work and wish to publish it and recieve a DOI, click Prepare to Publish in the Publication Preview.

There are 5 stages in the publication process:
Selection, Proofread Project, Proofread Data, Order Authors, and Licenses
In Selection, select which files you want to publish.
In Proofread Project & Data, take time to proofread all the metadata and tags you have entered. You cannot make changes after publishing.
In Order Authors, order the authors of the publication and preview how your citation will appear.
In Licenses, select one or more licenses that best fit your data.
Finally, click Request DOI & Publish and agree to the agreement to publish your work.
Best Practices¶
Data Collections Development¶
Accepted Data ¶
The DDR accepts engineering datasets generated through simulation, hybrid simulation, experimental, and field research methods regarding the impacts of wind, earthquake, and storm surge hazards, as well as debris management, fire, and blast explosions. We also accept social and behavioral sciences (SBE) data encompassing the study of the human dimensions of hazards and disasters. As the field and the expertise of the community evolves we have expanded our focus to include datasets related to COVID-19. Data reports, publications of Jupyter notebooks, code, scripts, lectures, and learning materials are also accepted.
Accepted and Recommended File Formats ¶
Due to the diversity of data and instruments used by our community, there are no current restrictions on the file formats users can upload to the DDR. However, for long-term preservation and interoperability purposes, we recommend and promote storing and publishing data in open formats, and we follow the Library of Congress Recommended Formats.
In addition, we suggest that users look into the Data Curation Primers, which are "peer-reviewed, living documents that detail a specific subject, disciplinary area or curation task and that can be used as a reference to curate research data. The primers include curation practices for documenting data types that while not open or recommended, are very established in the academic fields surrounding Natural Hazards research such as Matlab and Microsoft Excel.
Below is an adaptation of the list of recommended formats for data and documentation by Stanford Libraries. For those available, we include a link to the curation primers:
- Databases: XML, CSV
- Geospatial: SHP, DBF, GeoTIFF, netCDF, GeoJSON
- PointCloud: LAS, LAZ, XYZ, PTX
- Moving images: MOV, MPEG, AVI, MXF
- Sounds: WAVE, AIFF, MP3, MXF
- Statistics: ASCII, DTA, POR, SAS, SAV
- Still images: TIFF, JPEG 2000, PDF, PNG, GIF, BMP
- Tabular data: CSV
- Text: XML, PDF/A, HTML, ASCII, UTF-8 ,
- CODE: (tcl files, py files) Jupyter Notebook
- Seismology: SEED
Data Size¶
Currently we do not pose restrictions on the volume of data users upload to and publish in the DDR. This is meant to accommodate the vast amount of data researchers in the natural hazards community can generate, especially during the course of large-scale research projects.
However, for data curation and publication purposes users need to consider the sizes of their data for its proper reuse. Publishing large amounts of data requires more curation work (organizing and describing) so that other users can understand the structure and contents of the dataset. In addition, downloading very large projects may require the use of Globus. We further discuss data selection and quality considerations in the Data Curation section.
Data Curation¶
Data curation involves the organization, description, quality control, preservation, accessibility, and ease of reuse of data, with the goal of making your data publication FAIR with assurance that it will be useful for generations to come.
Extensive support for data curation can be found in the Data Curation and Publication User Guides and in Data Curation Tutorials. In addition, we strongly recommend that users follow the step by step onboarding instructions available in the My Projects curation interface. Virtual Office Hours are also available twice a week.
Below we highlight general curation best practices.
Managing and Sharing Data in My Projects¶
All data and documentation collected and generated during a research project can be uploaded to My Project from the inception of the project. Within My Project, data are kept private for sharing amongst team members and for curation until published. Using My Project to share data with your team members during the course of research facilitates the progressive curation of data and its eventual publication.
However, when conducting human subjects research, you must follow and comply with the procedures submitted to and approved by your Institutional Review Board (IRB) as well as your own ethical commitment to participants for sharing protected data in My Project.
Researchers working at a NHERI EF will receive their bulk data files directly into an existing My Project created for the team.
For all other research performed at a non-NHERI facility, it will be the responsibility of the research team to upload their data to the DDR.
There are different ways to upload data to My Project:
- Do not upload folders and files with special characters in their filenames. In general, keep filenames meaningful but short and without spacing. See file naming convention recommendations in the Data Organization and Description
- Select the Add button, then File upload to begin uploading data from your local machine. You can browse and select files or drag and drop files into the window that appears.
- Connect to your favorite cloud storage provider. We currently support integration with Box, Dropbox, and Google Drive.
- You can also copy data to and from My Data.
- You may consider zipping files for purpses of uploading: however, you should unzip them for curation and publication purposes.
- For uploads of files bigger than 2 Gigabytes and or more than 25 files, consider using Globus, CyberDuck and Command Line Utilities. Explanations on how to use those applications are available in our Data Transfer Guide.
Downloading several individual files via our web interface could be cumbersome, so DesignSafe offers a number of alternatives. First, users may interact with data in the Workspace using any of the available tools and applications without the need to download; for this, users will need a DesignSafe account. Users needing to download a large number of files from a project may also use Globus. When feasible, to facilitate data download from their projects users may consider aggregating data into larger files.
Be aware that while you may store all of a project files in My Project, you may not need to publish all of them. During curation and publication you will have the option to select a subset of the uploaded files that you wish to publish without the need to delete them.
More information about the different Workspaces in DesignSafe and how to manage data from one to the other can be found here.
Selecting a Project Type¶
Depending on the research method pursued, users may curate and publish data as "Experimental", "Simulation", "Hybrid Simulation," or "Field Research" project type. The Field Research project type accommodates "Interdisciplinary Datasets" involving engineering and/or social science collections.
Based on data models designed by experts in the field, the different project types provide interactive tools and metadata forms to curate the dataset so it is complete and understandable for others to reuse. So for example,users that want to publish a simulation dataset will have to include files and information about the model or software used, the input and the output files, and add a readme file or a data report.
Users should select the project type that best fits their research method and dataset. If the data does not fit any of the above project types, they can select project type" Other." In project type "Other" users can curate and publish standalone reports, learning materials, white papers, conference proceedings, tools, scripts, or data that does not fit with the research models mentioned above.
Working in My Project¶
Once the project type is selected, the interactive interface in My Project will guide users through the curation and publication steps through detailed onboarding instructions.
My Project is a space where users can work during the process of curation and publication and after publication to publish new data products or to analyze their data.
Because My Project is a shared space, it is recommended that teams select a data manager to coordinate file organization, transfers, curation, naming, etc.
After data is published users can still work on My Project for progressive publishing of new experiments, missions or simulations within the project, to version and/or to edit or amend the existing publication. See amends and versions in this document.
General Research Data Best Practices¶
Below we include general research data best practices but we strongly recommend to review the available Data Curation Primers for more specific directions on how to document and organize specific research data types.
Proprietary Formats¶
Excel and Matlab are two proprietary file formats highly used in this community. Instead of Excel spreadsheet files, it is best to publish data as simple csv so it can be used by different software. However, we understand that in some cases (e.g. Matlab, Excel) conversion may distort the data structures. Always retain an original copy of any structured data before attempting conversions, and then check between the two for fidelity. In addition, in the DDR it is possible to upload and publish both the proprietary and the converted version, especially if you consider that publishing with a proprietary format is convenient for data reuse.
Compressed Data¶
Users that upload data as a zip file should unzip before curating and publishing, as zip files prevent others from directly viewing and understanding the published data. If uploading compressed files to "My Data" , it is possible to unzip it using the extraction utility available in the workspace before copying data to My Project for curation and publication.
Simulation Data¶
In the Data Depot's Published directory there is a best practices document for publishing simulation datasets in DesignSafe. The topics addressed reflect the numerical modeling community needs and recommendations, and are informed by the experience of the working group members and the larger DesignSafe expert cohort while conducting and curating simulations in the context of natural hazards research. These best practices focus on attaining published datasets with precise descriptions of the simulations’ designs, references to or access to the software involved, and complete publication of inputs and if possible all outputs. Tying these pieces together requires documentation to understand the research motivation, origin, processing, and functions of the simulation dataset in line with FAIR principles. These best practices can also be used by simulation researchers in any domain to curate and publish simulation data in any repository.
Geospatial Data¶
We encourage the use of open Geospatial data formats. Within DS Tools and Applications we provide two open source software for users to share and analyze geospatial data. QGIS can handle most open format datasets and HazMapper, is capable of visualizing geo-tagged photos and GeoJSON files. To access these software users should get an account in DesignSafe.
Understanding that ArcGIS software is widespread in this community in the DDR it is possible to upload both proprietary and recommended geospatial data formats. When publishing feature and raster files it is important to make sure that all of the relevant files for reuse such as the projection file and header file are included in the publication for future re-use. For example, for shapefiles it is important to publish all .shp (the file that contains the geometry for all features), .shx (the file that indexes the geometry) and .dbf (the file that stores feature attributes in a tabular format) files.
Point Cloud Data¶
It is highly recommended to avoid publishing proprietary point cloud data extensions. Instead, users should consider publishing post-processed and open format extension data such as las or laz files. In addition, point cloud data publications may be very large. In DS, we have Potree available for users to view point cloud datasets. Through the Potree Convertor application, non-proprietary point cloud files can be converted to a potree readable format to be visualized in DesignSafe.
Jupyter Notebooks¶
More and more researchers are publishing projects that contain Jupyter Notebooks as part of their data. They can be used to provide sample queries on the published data as well as providing digital data reports. As you plan for publishing a Jupyter Notebook, please consider the following issues:
- The DesignSafe publication process involves copying the contents of your project at the time of publication to a read only space within the Published projects section of the Data Depot (i.e., this directory can be accessed at NHERI-Published in JupyterHub). Any future user of your notebook will access it in the read only Published projects section. Therefore, any local path you are using while developing your notebook that is accessing a file from a private space (e.g., "MyData", "MyProjects") will need to be replaced by an absolute path to the published project. Consider this example: you are developing a notebook in PRJ-0000 located in your "MyProjects" directory and you are reading a csv file living in this project at this path:
/home/jupyter/MyProjects/PRJ-0000/Foo.csv. Before publishing the notebook, you need to change the path to this csv file to/home/jupyter/NHERI-Published/PRJ-0000/Foo.csv. - The published area is a read-only space. In the published section, users can run notebooks, but the notebook is not allowed to write any file to this location. If the notebook needs to write a file, you as the author of the notebook should make sure the notebook is robust to write the file in each user directory. Here is an example of a published notebook that writes files to user directories. Furthermore, since the published space is read-only, if a user wants to revise, enhance or edit the published notebook they will have to copy the notebook to their mydata and continue working on the copied version of the notebook located in their mydata. To ensure that users understand these limitations, we require a readme file be published within the project that explains how future users can run and take advantage of the Jupyter Notebook.
- Jupyter Notebooks rely on packages that are used to develop them (e.g., numpy, geopandas, ipywidgets, CartoPy, Scikit-Learn). For preservation purposes, it is important to publish a requirement file including a list of all packages and their versions along with the notebook as a metadata file.
Data Organization and Description¶
In My Projects, users may upload files and or create folders to keep their files organized; the latter is common when projects have numerous files. However, browsing through an extensive folder hierarchy on the web may be slower on your local computer, so users should try to use the smallest number of nested folders necessary and if possible, none at all, to improve all users’ experience.
Except for project type "Other" which does not have categories, users will categorize their files or folders according to the corresponding project type. Categories describe and highlight the main components of the dataset in relation to the research method used to obtain it. Each category has a form that needs to be filled with metadata to explain the methods and characteristics of the dataset, and there are onboarding instructions on what kind of information is suitable for each metadata field. In turn, some of these fields are required, which means that they are fundamental for the clarity of the project's description. The best way to approach data curation in My Project, is to organize the files in relation to the data model of choice and have the files already organized and complete before categorizing and tagging. While curating data in My Project, do not move, rename or modify files that have been already categorized. In particular, do not make changes to categorized files through an SSH connection or through Globus. If you need to, please remove the category, deselect the files, and start all over.
Within the different project types, there are different layers for describing a dataset. At the project level, it is desirable to provide an overview of the research, including its general goal and outcomes, what is the audience, and how the data can be reused. For large projects we encourage users to provide an outline of the scope and contents of the data. At the categories level, the descriptions need to address technical and methodological aspects involved in obtaining the data.
In addition, users can tag individual files or groups of files for ease of data comprehension and reuse by others. While categories are required, tagging is not, though we recommend that users tag their files because it helps other users to efficiently identify file contents in the publication interface. For each project type the list of tags are agreed upon terms contributed by experts in the field of NH. If the tags available do not apply, feel free to add custom tags and submit tickets informing the curation team about the need to incorporate them in the list. We heard from our users that the list of tags per category reaffirms them of the need to include certain types of documentation to their publication.
To enhance organization and description of projects type "Other," users can group files in folders when needed and use file tags. However, it is always best to avoid overly nesting and instead use the file tags and descriptions to indicate what are the groupings.
File naming conventions are often an important part of the work of organizing and running large scale experimental and simulation data. File names make it possible to identify files by succintly expressing their content and their relations to other files. File naming conventions should be established during the research planning phase, they should be meaningful -to the team and to others- and they should be kept short. When establishing a file naming convention, researchers should think about the key information elements they want to convey for others to identify tiles and group of files. The meaning and components of file naming conventions should be documented in a Data Report or readme file so that others can understand and identify files as well. Users should consider that in DesignSafe you will be able to describe files with tags and descriptions when you curate them. File naming conventions should not have spaces or special characters, as those features may cause errors within the storage systems. See this Stanford University Libraries best practices for file naming convention.
The following are good examples of data organization and description of different project types:
-
Experimental
-
Simulation
-
Hybrid Simulation
-
Field Research
-
Interdisciplinary Field Research
-
Other
Project Documentation¶
NH datasets can be very large and complex, so we require that users submit a data report or a readme file to publish along with their data to express information that will facilitate understanding and reuse of your project. This documentation may include the structure of the data, a data dictionary, information of where everything is, explanation of the file naming convention used, and the methodology used to check the quality of the data. The data report in this published dataset is an excellent example of documentation.
To provide connections to different types of information about the published dataset, users can use the Related Work field. We provide different types of tags that explain their relation to the dataset. To connect to information resources that provide contextual information about the dataset (events or organizations) use the tag "context". To link to other published datasets in the DDR use the tag "link Dataset", and to connect to published papers that cite the dataset use the tag "is cited by". Importantly, users should add the DOI of these different information types in http format (if there is no DOI add a URL). The latter information is sent to DataCite, enabling exchange of citation counts within the broader research ecosystem through permanent identifiers. Related Works can be added after the dataset was published using the amends pipeline. This is useful when a paper citing the dataset is published after the publication of the dataset.
When applicable, we ask users to include information about their research funding in the Awards Info fields.
Data Quality Control¶
Each data publication is unique; it reflects and provides evidence of the research work of individuals and teams. Due to the specificity, complexity, and scope of the research involved in each publication, the DDR cannot complete quality checks of the contents of the data published by users. It is the user's responsibility to publish data that is up to the best standards of their profession, and our commitment is to help them achieve these standards. In the DDR, data and metadata quality policies as well as the curation and publication interactive functions are geared towards ensuring excellence in data publications. In addition, below we include general data content quality recommendations:
Before publishing, use applicable methods to review the data for errors (calibration, correction, validation, normalization, completeness checks) and document the process so that other reusers are aware of the quality control methods employed. Include the explanation about the quality control methods you used in the data report or readme file.
Include a data dictionary or a readme file to explain the meaning of data fields.
Researchers in NH generate enormous amounts of images. While we are not posing restrictions on the amount of files, in order to be effective in communicating their research users being selective with the images chosen to publish is key. For example, making sure they have a purpose, are illustrative of a process or a function, and using file tags to describe them. The same concept can be applied for other data formats.
It is possible to publish raw and curated data. Raw data is that which comes directly from the recording instruments (camera, apps, sensors, scanners, etc). When raw data is corrected, calibrated, reviewed, edited or post-processed in any way for publication, it is considered curated. Some researchers want to publish their raw data as well as their curated data. For users who seek to publish both, consider why it is necessary to publish both sets and how another researcher would use them. Always clarify whether your data is raw or curated in the description or in a data report/readme file including the method used to post-process it.
Managing Protected Data in the DDR¶
Users that plan to work with human subjects should have their IRB approval in place prior to storing, curating, and publishing data in the DDR. We recommend following the recommendations included in the CONVERGE series of check sheets that outline how researchers should manage/approach the lifecycle data that contain personal and sensitive information; these check sheets have also been published in the DDR.
At the moment of selecting a Field Research project, users are prompted to respond if they will be working with human subjects. If the answer is yes, the DDR curator is automatically notified and gets in touch with the project team to discuss the nature and conditions of the data and the IRB commitments.
DesignSafe My Data and My Projects are secure spaces to store raw protected data as long as it is not under HIPAA, FERPA or FISMA regulations. If data needs to comply with these regulations, researchers must contact DDR through a help ticket to evaluate the need to use TACC‘s Protected Data Service. Researchers with doubts are welcome to send a ticket or join curation office hours.
Projects that do not include the study of human subjects and are not under IRB purview may still contain items with Personally Identifiable Information (PII). For example, researchers conducting field observations may capture human subjects in their documentation including work crews, passersby, or people affected by the disaster. If camera instruments capture people that are in the observed areas incidentally, we recommend that their faces and any Personally Identifiable Information should be anonymized/blurred before publishing. In the case of images of team members, make sure they are comfortable with making their images public. Do not include roofing/remodeling records containing any form of PII. When those are public records, researchers should point to the site from which they are obtained using the Referenced Data and or Related Work fields. In short, users should follow all other protected data policies and best practices outlined further in this document.
Metadata Requirements¶
Metadata is information that describes the data in the form of schemas. Metadata schemas provide a structured way for users to share information about data with other platforms and individuals. Because there is no standard schema to describe natural hazards engineering research data, the DDR developed data models containing elements and controlled terms for categorizing and describing NH data. The terms have been identified by experts in the NH community and are continuously expanded, updated, and corrected as we gather feedback and observe how researchers use them in their publications.
So that DDR metadata can be exchanged in a standard way, we map the fields and terms to widely-used, standardized schemas. The schemas are: Dublin Core for description of the research data project, DDI (Data Documentation Initiative) for social science data, and DataCite for DOI assignment and citation. We use the PROV schema to connect the different components of multi-part data publications.
Due to variations in research methods, users may not need to use all the metadata elements available to describe their data. However, for each project type we identified a required set that represents the structure of the data, are useful for discovery, and will allow proper citation of data. To ensure the quality of the publications, the system automatically checks for completeness of these core elements and whether data files are associated with them. If those elements and data are not present, the publication does not go through. For each project type, the metadata elements including those that are required and recommended are shown below.
| Experimental Research Project View Metadata Dictionary
|
Simulation Research Project View Metadata Dictionary
|
| Hybrid Simulation Research Project View Metadata Dictionary
|
Field Research Project View Metadata Dictionary
|
| Other View Metadata Dictionary
|
Data Publication¶
Protected Data¶
Protected data in the Data Depot Repository (DDR) are generally (but not always) included within interdisciplinary and social science research projects that study human subjects, which always need to have approval from an Institutional Review Board (IRB). We developed a data model and onboarding instructions in coordination with our CONVERGE partners to manage this type of data within our curation and publication pipelines. Additionally, CONVERGE has a series of check sheets that outline how researchers should manage data that could contain sensitive information; these check sheets have also been published in the DDR.
Natural Hazards also encompasses data that have granular geographical locations and images that may capture humans that are not the focus of the research/would not fall under the purview of an IRB. See both the Privacy Policy within our Terms of Use,
Data de-identification, specially for large datasets, can be tasking. Users working with the RAPID facility may discuss with them steps for pre-processing before uploading to DesignSafe.
To publish protected data researchers should pursue the following steps and requirements:
- Do not publish HIPAA, FERPA, FISMA, PII data or sensitive information in the DDR.
- To publish protected data and any related documentation (reports, planning documents, field notes, etc.) it must be processed to remove identifying information. No direct identifiers and up to three indirect identifiers are allowed. Direct identifiers include items such as participant names, participant initials, facial photographs (unless expressly authorized by participants), home addresses, phone number, email, vehicle identifiers, biometric data, names of relatives, social security numbers and dates of birth or other dates specific to individuals. Indirect identifiers are identifiers that, taken together, could be used to deduce someone’s identity. Examples of indirect identifiers include gender, household and family compositions, places of birth, or year of birth/age, ethnicity, general geographic indicators like postal code, socioeconomic data such as occupation, education, workplace or annual income.
- Look at the de-identification resources below to find answers for processing protected data.
- If a researcher has obtained consent from the subjects to publish PII (images, age, address), it should be clearly stated in the publication description and with no exceptions the IRB documentation including the informed consent statement, should be also available in the documentation.
- If a researcher needs to restrict public access to data because it includes HIPAA, FERPA, PII or other sensitive information, or if de-identification precludes the data from being meaningful, it is possible to publish only metadata about the data in the landing page along with descriptinve information a bout the dataset. The dataset will show as Restricted.
- IRB documentation should be included in the publication in all cases so that users clearly understand the restrictions imposed for the protected data. In addition, authors may publish the dataset instrument, provided that it does not include any form of protected information.
- Users interested in restricted data can contact the project PI or designated point of contact through their published email address to request access to the data and to discuss the conditions for its reuse.
- The responsibility of maintaining and managing a restricted dataset for the long term lies on the authors, and they can use TACC's Protected Data Services if they see fit.
- Please contact DDR through a help ticket or join curation office hours prior to preparing this type of publication.
De-identification Resources¶
The NISTIR 8053 publication De-Identification of Personal Information provides all the definitions and approaches to reduce privacy risk and enable research.
Another NIST resource including de-identification tools.
John Hopkins Libraries Data Services Applications to Assist in De-identification of Human Subjects Research Data.
Reusing Data Resources in your Publication¶
Researchers frequently use data, code, papers or reports from other sources in their experiments, simulations and field research projects as input files, to integrate with data they create, or as references, and they want to republish them. It is a good practice to make sure that this data can be reused appropriately and republished as well as give credit to the data creators. Citing reused sources is also important to provide context and provenance to the project. In the DDR you can republish or reference reused data following the next premises:
- If you use external data in a specific experiment, mission or simulation, cite it in the Referenced Data field.
- Use the Related Work field at project level to include citations for the data you reused as well as your own publication related to the data reuse.
- Include the cited resource title and corresponding DOI in https format; this way, users will be directed to the cited resource.
- Be aware of the reused data original license. The license will specify if and how you can modify, distribute, and cite the reused data.
- If you have reused images from other sources (online, databases, publications, etc.), be aware that they may have copyrights. We recommend using these instructions for how to use and cite them.
Timely Data Publication ¶
Although no firm timeline requirements are specified for data publishing, researchers are expected to publish in a timely manner. Recommended timelines for publishing different types of research data (i.e., Experimental, Simulation, and Reconnaissance) are listed in Table 1.
Guidelines specific to RAPID reconnaissance data can be found at rapid.designsafe-ci.org/media/filer_public/b3/82/b38231fb-21c9-41f8-b658-f516dfee87c8/rapid-designsafe_curation_guidelines_v3.pdf
Table 1. Recommended Publishing Timeline for Different Data Types¶
| Project/Data Type | Recommended Publishing Timeline |
| Experimental | 12 months from completion of experiment |
| Simulation | 12 months from completion of simulations |
| Reconnaissance: Immediate Post-Disaster | 3 months from returning from the field |
| Reconnaissance: Follow-up Research | 6 months from returning from the field |
Public Accessibility Delay¶
Some journals require that researchers submitting a paper for review inlcude the corresponding dataset DOI in the manuscript. Data accessibility delay or embargo refers to time during which a dataset has a DOI but it is not made broadly accessible, awaiting for the review to be accepted by a journal paper.
In August 25, 2022 the Office of Science and Technology Policy issued a memorandum with policy guidelines to “ensure free, immediate and equitable access to federally funded research.” In the spirit of this guidance, DesignSafe has ceased offering data accessibility delays or embargos. DesignSafe continues working with users to:
- Provide access to reviewers via My Projects before the dataset is published. There is no DOI involved and the review is not annonymous.
- Help users curate and publish their datasets so they are publicly available for reviewers in the best possible form.
- Provide amends and versioning so that prompt changes can be made to data and metadata upon receiving feedback from the reviewers or at any other time.
In addition, DesignSafe Data Depot does not offer capabilities for enabling single or double blind peer review.
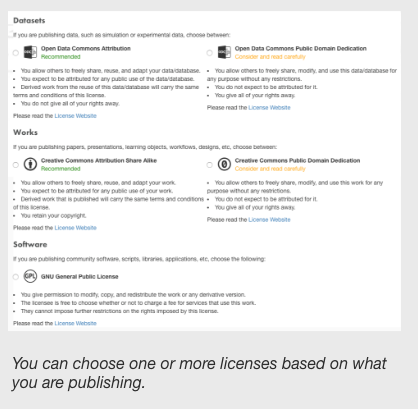
Licensing¶
Within DesignSafe, you will choose a license to distribute your material. The reason for offering licences with few restrictions, is that by providing less demands on reusers, they are more effective at enabling reproducible science. We offere licenses with few to no restrictions. By providing less demands on reusers, they are more effective at enabling reproducible science. Because the DesignSafe Data Depot is an open repository, the following licenses will be offered:
- For datasets: ODC-PDDL and ODC-BY
- For copyrightable materials (for example, documents, workflows, designs, etc.): CC0 and CC-BY
- For code: GPL
You should select appropriate licenses for your publication after identifying which license best fits your needs and institutional standards. Note that datasets are not copyrightable materials, but works such as reports, instruments, presentations and learning objects are.
Please select only one license per publication with a DOI.
Available Licenses for Publishing Datasets in DesignSafe
DATASETS¶
If you are publishing data, such as simulation or experimental data, choose between:
| Open Data Commons Attribution
Recommended for datasets
|
|
| Open Data Commons Public Domain Dedication
Consider and read carefully
|
|
WORKS¶
If you are publishing papers, presentations, learning objects, workflows, designs, etc, choose between:
| Creative Commons Attribution
Recommended for reports, instruments, learning objects, etc.
|
|
| Creative Commons Public Domain Dedication
Consider and read carefully
|
|
SOFTWARE¶
If you are publishing community software, scripts, libraries, applications, etc, choose the following:
| GNU General Public License |
|
Subsequent Publishing¶
With the exception of Project Type Other, which is a one time publication, in the DDR it is possible to publish datasets or works subsequently. A project can be conceived as an umbrella where reports or learning materials, code, and datasets from distinct experiments, simulations, hybrid simulations or field research missions that happen at different time periods, involve participation of distinct authors, or need to be released more promptly, can be published at different times. Each new product will have its own citation and DOI, and users may select a different license if that is appropriate for the material, (e.g. a user publishing a data report will use a Creative Commons license, and an Open Data Commons license to publish the data). The subsequent publication will be linked to the umbrella project via the citation, and to the other published products in the project through metadata.
After a first publication, users can upload more data and create a new experiment/simulation/hybrid simulation or mission and proceed to curate it. Users should be aware that momentarily they cannot publish the new product following the publication pipeline. After curation and before advancing through the Publish My Project button, they should write a help ticket or attend curation office hours so that the DDR team can assist and publish the new product.
Amends and Version Control ¶
Once a dataset is published users can do two things to improve and or / continue their data publication: amends and version control. Amends involve correcting certain metadata fields that do not incur major changes to the existing published record, and version control includes changes to the data. Once a dataset is published, however, we do not allow title or author changes. If those changes need to be made due to omission or mistake, users have to submit a Help ticket and discuss the change with the data curator. If applicable, changes will be done by the curation team.
Amends include:
- Improving descriptions: often after the curator reviews the publicationn, or following versioning, users need to clarify or enhance descriptions.
- Adding related works: when papers citing a dataset are published we encourage users to add the references in Related Works to improve data understandibility and cross-referencing and citation count.
- Changing the order of authors: even though DDR has interactive tools to set the order of authors in the publication pipeline, users further require changes after publication due to oversight.
Version control includes:
- Adding or deleting files to a published dataset.
- Documenting the nature of the changes which will publicly show in the landing page.
- Descriptions of the nature of the changes are displayed for users to see what changed and stored as metadata.
- In the citation and landing pages, different versions of a dataset will have the same DOI and different version number.
- The DOI will always resolve to the latest version of the data publication.
- Users will always be able to access previous versions through the landing page.
When implementing amend and version take the following into consideration:
Amend is only going to update the latest version of a publication (if there is only one version that will be the target). Only the specified fields in the metadata form will be updated. The order of authors must be confirmed before the amendments can be submitted.
Version will create a new published version of a project. This pipeline will allow you to select a new set of files to publish, and whatever is selected in the pipeline is what will be published, nothing else. Additionally, the order of authors can be updated.
Important: Any changes to the project’s metadata will also be updated (this update is limited to the same fields allowed in the Amend section), so there is no need to amend a newly versioned project unless you have made a mistake in the latest version.
Leave Data Feedback¶
We welcome feedback from users about the published datasets. For this, users can click on the "Leave Feedback" button at the top of the data presentation on the data publication landing pages. We suggest that feedback is written in a positive, constructive language. The following are examples of feedback questions and concerns:
- Questions about the dataset that are not answered in the published metadata and or documentation.
- Missing documentation.
- Questions about the method/instruments used to generate the data.
- Questions about data validation.
- Doubts/concerns about data organization and or inability to find desired files.
- Interest in bibliography about the data/related to the data.
- Interest in reusing the data.
- Comments about the experience of reusing the data.
- Request to access raw data if not published.
- Congratulations.
Marketing Datasets¶
Datasets take a lot of work to produce; they are important research products. By creating a complete, organized, and clearly described publication in DDR, users are inviting others to reuse and cite their data. Researchers using published data from DDR must cite it using the DOI, which relies on the DataCite schema for accurate citation. For convenience, users can retrieve a formatted citation from the published data landing page. It is recommended to insert the citations in the reference section of the paper to facilitate citation tracking and count.
When using social media or any presentation platform to communicate research, it is important to include the proper citation and DOI on the presentations, emails, tweets, professional blog posts, etc.. A researcher does not actually need to reuse a dataset to cite it, but rather may cite it to point/review something about a dataset (e.g., how it was collected, its uniqueness, certain facts, etc.). This is similar to the process of citing other papers within a literary review section.
Data Preservation¶
In the Data Depot Repository (DDR) data preservation is achieved through the combined efforts of the NH community that submits data and metadata following policies and best practices, and the DDR's administrative responsibilities and technical capabilities. The following data preservation best practices ensure preservation of the data from the moment in which researchers plan their data projects and for the long term after the data is published.
Depositing your data and associated research project materials in the DDR meets NSF requirements for data management. See our Data Management Plan.
Follow the curation and publication onboarding instructions and steps -documented in the Data Curation and Publication Guides - to ensure that your data curation and publication process is smooth and that your public datasets are well organized, complete, and understandable to others.
To facilitate long term access to your published data, when possible, we recommend using open file formats. Open file formats facilitate interoperability between datasets and with applications, which in turn facilitates long term access to the datasets.
DDR data is stored in high performance storage (HPC) resources deployed at the Texas Advanced Computing Center. These storage resources are reliable, secure, monitored 24/7, and under a rigorous maintenance and update schedule.
While you are uploading and working with your data in DDR, your data is safe and geographically replicated in Corral, TACC's storage and data management resource.
DDR operates a dedicated open source Fedora 5.x digital repository. Once the dataset is curated and the user has agreed to the last step in the publication process, the data and the metadata that the user has been inputting throughout the curation processare sent to Fedora where each published dataset contains linkages between datastreams, versions, metadata, and system metadata. At ingest, Fedora metadata records are created and publication binaries are bundled with a hash (fixity) and stored on Corral in a secure location that is recorded on the metadata (See Fedora data model). For each individual file, Fedora generates and maintains preservation metadata in the standard PREMIS format.
In the case of the DDR, file system replication is automatic. Ingestion of data from the web-visible storage into Fedora takes place under automated control when the publication workflow executes. The Fedora repository and database is likewise replicated as well as backed up on an automated schedule. Metadata preservation is assured through the backup of Fedora's metadata database. In case of failure where data is compromised, we can restore the system from the replication.
Both the front-end copies and the Fedora repositories are in systems that implement de-clustered RAID and have sufficient redundancy to manage up to 3 drive failures for a single file stripe. The file system itself is mirrored daily between two datacenters. The primary data is also periodically backed up to a tape archive for a third copy, in a third datacenter. The database that manages metadata in Fedora is also quiesced, snapshotted, and backed to tape on a regular automated schedule.
The underlying storage systems for the DDR are managed in-house at TACC. All the storage systems used by DesignSafe are shared multi-tenant systems, hosting many projects concurrently in addition to DesignSafe – the front-end disk system currently has ~20PB of data, with the tape archive containing roughly 80PB. These systems are operated in production by a large team of professional staff, in conjunction with TACC’s supercomputing platforms. Public user guides document the capabilities and hardware, and internal configuration management is managed via Redmine, visible only to systems staff.
This preservation environment allows maintaining data in secure conditions at all times, before and after publication, comply with NDSA Preservation Level 1, attain and maintain the required representation and descriptive information about each file, and be ready at any time to transfer custody of published data and metadata in an orderly and validated fashion. Fedora has export capabiiities for transfer of data and metadata to another Fedora repository or to another system.
Each published dataset has a digital object identifier (DOI) that provides a persistent link to the published data. The DOI is available in the dataset landing page, along with all the required metadata and documentation.
To learn about our commitment to data preservation, please read our Digital Preservation Policy.
Data Depot/Curation Office Hours¶
NHERI Virtual Office Hours¶
Virtual Office hours is the newest way to connect with experts in the NHERI network. Using the links below, schedule a time to meet with facility personnel to answer your questions. If you don’t see the facility you are interested in, email us at eco-feedback@designsafe-ci.org.
DesignSafe Data Depot/Curation¶

DesignSafe’s Data Curator, Dr. Maria Esteva, holds virtual office hours every Tuesday and Thursday from 1:00pm to 2:00pm CT (via Zoom) to assist you with your data curation and publication. Reservations are not required, simply connect to the Zoom feed during this time.
Connect to Office Hours
Meeting ID: 730 745 593
Passcode: 595633
DesignSafe Workspace¶

Dr. Wenyang Zhang holds virtual office hours every other Tuesday from 2:00pm to 3:00pm CT (via Zoom) beginning Sep 27, 2022, to assist you with applying your research using the various Tools & Applications or with managing your files in the Data Depot. Reservations are not required, simply connect to the Zoom feed during this time.
Connect to Office Hours
Meeting ID: 921 9925 2248
Passcode: 776504
Florida International University, Wall of Wind¶

The Wall of Wind Research Scientists are available to meet with you every Wednesday between 3:00-5:00 pm EST.
Lehigh University, Real-Time Multi-Directional Experimental Facility¶

Lehigh’s Dr. Liang Cao is available to answer questions and discuss research proposals every other Wednesday from 2:00-3:00 pm EST.
University of California, San Diego, Large High Performance Outdoor Shake Table¶

Dr. Koorosh Lotfizadeh, NHERI USCD Interim NHERI Operations Manager, is available to answer your questions and discuss research proposals the first and third Tuesday of the month from 1:00-2:00 pm PDT.
Contact Dr. Lotfizadeh: klotfiza@ucsd.edu Sign Up for Office Hours
Oregon State University, O.H. Hinsdale Wave Research Laboratory¶

Dr. Pedro Lomonaco, Co-Pi and Director of NHERI O.H. Hinsdale Wave Research Laboratory, is available to answer your questions and discuss research proposals. Schedule a time to meet by emailing him below.
Contact Dr. Lomonaco: pedro.lomonaco@oregonstate.edu
How to Schedule Virtual Office Hours¶
To schedule a meeting with NHERI facility faculty, click the facility Eventbrite link, schedule your date and time, chose individual or group meeting, and then register. A confirmation email will include the Zoom link for your scheduled day and time. You will also receive reminder emails about your scheduled meeting. Also see our video tutorial.
Questions? Email: eco-feedback@designsafe-ci.org
Metrics Documentation¶
Data Metrics¶
Data metrics are research impact indicators complementary to other forms of evaluation such as number of paper citations, allowing researchers to assess the repercussions and influence of their work.
Metrics available in DesignSafe follow the Make your Data Count Counter Code of Practice for Research Data. This is a community standard to count data usage transparently and in a normalized way. For more information about this approach please visit Make your Data Count Metrics.
In Natural Hazards, a research project can encompass more than one data publication which can be produced at different times by different creators and have different DOIs. In DesignSafe, project types are: Other, Experimental, Simulation, Hybrid Simulation, and Field Research. In turn, each has different data publications. Project type "Other" only has one data publication and DOI, while the rest may have more than one data publication and therefore multiple DOIs per project.
Data Publications:
Experiment (in Experimental projects)
Mission and Document collection (in Field Research projects)
Simulation (in Simulation projects)
Hybrid Simulation (in Hybrid Simulation projects)
Other-type project (these encompass only one data publication and thus one level of metrics).
Because of the structure of the research projects in DesignSafe we report metrics at the project and at the data publication levels. Metrics at the project level allow researchers to assess the overall impact of the projects because it aggregates the usage of all the data publications. Instead, data publication metrics provide granular information about the usage of each publication that has a DOI within a project.
Data Metrics is a work in progress and we add measurements on an ongoing basis. We started counting Project Metrics in March 2021 And Data Publication Metrics in January 2022.
Below are descriptions of each type of metric and what is counted at the project and at the data publication levels.
Project Metrics¶
File Preview: Examining data in any data publication within a project such as clicking on a file name brings up a modal window that allows previewing the files. However, not all data types can be previewed. Among those that can are: text, spreadsheets, graphics and code files. (example extensions: .txt, .doc, .docx, .csv, .xlsx, .pdf, .jpg, .m, .ipynb). Those that can't include binary executables, MATLAB containers, compressed files, and video (eg. .bin, .mat, .zip, .tar, mp4, .mov). Only those files that can be previewed are counted. Users will get a count of all the files that have been previewed in the entire project.
File Download: Copying a file to the machine the user is running on, or to a storage device that the machine has access to. This can be done by ticking the checkbox next to a file and selecting "Download" at the top of the project page. With files that can be previewed, clicking "Download" at the top of the preview modal window has the same effect. Downloads are counted per project. We also consider counts when users tick the checkbox next to a document and select "Copy" at the top of the project page. The counts of copying a file from the published project can be to the user's My data, My projects, to Tools and Applications in the Workspace, or to one of the connected spaces (Box, Dropbox, Google Drive). Users will get a count of all the files that have been downloaded in the entire project.
File Requests: Total file downloads + total file previews. This is counted and aggregated for all data publications that have a DOI within a project (eg. Simulation, Experiment, Mission, Hybrid simulation and Documents Collection). Users will get a count of all the files that have been requested in the entire project.
Total Investigations: File requests + metadata views. Viewing the main project information / metadata in the landing page counts as an investigation of each DOI included in the project. Opening a data publication (eg. simulation, experiment, documents collection, mission, hybrid simulation) counts as one investigation of that specific data publication.Requests and metadata views at the data publication level are counted and aggregated at the project level metrics.
Project Downloads: Total downloads of a compressed entire project and its metadata to a user's machine.
Data Publication Metrics¶
File Preview: Examining data from an individual data publication such as clicking on a file name brings up a modal window that allows previewing files. Those file previews are counted. However, not all document types can be previewed. Among those that can are: text, spreadsheets, graphics and code files. (example extensions: .txt, .doc, .docx, .csv, .xlsx, .pdf, .jpg, .m, .ipynb). Those that can't include binary executables, MATLAB containers, compressed files, and video (eg. .bin, .mat, .zip, .tar, mp4, .mov). Only those files that can be previewed are counted. Users will get a count of all the files that have been previewed in the data publication.
File Download: Copying a file to the machine the user is running on, or to a storage device that the machine has access to. This can be done by ticking the checkbox next to a file and selecting "Download" at the top of the project page. With files that can be previewed, clicking "Download" at the top of the preview modal window has the same effect. Downloads are counted per individual files. We also consider counts when users tick the checkbox next to a file and select "Copy" at the top of the project page. The counts of copying a file from the published project can be to the user's My data, My projects, to Tools and Applications in the Workspace, or to one of the connected spaces (Box, Dropbox, Google Drive).
File Requests: Total file downloads + total file previews. This is counted for each data publication that has a DOI (eg. Simulation, Experiment, Mission, Hybrid simulation and Documents Collection).
Session: All activity during one clock hour from a single IP address and user-agent (a string that identifies the user's browser and operating system.). This is used as a proxy to define a session to count unique requests and unique investigations.
Unique Requests: Any downloads, previews, copies of files, or project downloads from a single data publication (DOI) by a user in a single session counts as 1 Unique Request. This is counted for each data publication with a single DOI including Simulations, Hybrid Simulations, Experiments, Missions, Documents Collection and type Other projects.
Total Investigations: File requests + metadata views. Reading the metadata (information about the project and or the data publication) on the landing page counts as an investigation of each data publication with a DOI included in a project. Opening a data publication counts as one investigation of that data publication.
Unique Investigations: Any viewing of metadata and any downloads, previews, copies of files or project downloads from a single data publication (DOI) by a user in a single session counts as 1 Unique Investigation. This is counted for each data publication with a single DOI including Simulations, Hybrid Simulations, Experiments, Missions, Documents Collection and type Other projects.
Curation & Publication FAQ¶
Selecting Files & Data¶
Q: What are the best file formats for data publications?
A: For long-term preservation purposes it is best to publish data in interoperable and open formats. For example, instead of Excel spreadsheet files -which are proprietary- it is best to convert them to CSV for publication. And, instead of Matlab files -also proprietary- it is best to publish data as simple txt (ascii) so it can be used by many different software. However, be aware that conversion may distort the data structure, so retain an original copy of any structured data (e.g. Matlab, Excel files) before attempting conversions and then check between the two for fidelity. In addition, you may publish both the proprietary and the open format, and/or consult the Data Curation Primers to find out how to better curate research data.
Q: What does DesignSafe recommend for zip files?
A: If you uploaded your data as zip files, you should unzip before publishing. Zip files prevent others from directly viewing and understanding your data in the cloud. You may upload zip files to your "MyData" and unzip them using the utilities available in the workspace at: https://www.designsafe-ci.org/rw/workspace/#!/extract-0.1u1 before copying them to your project.
Q: My project has many individual files. It will be cumbersome for a user to download them one by one. What do you suggest?
A: Through the web interface, downloading a lot of individual files is cumbersome. However, DesignSafe offers a number of solutions for this issue. First, users may interact with data in the cloud, without the need to download, using Matlab scripts as well as Jupyter notebooks. In this case, users may find downloading large quantities of data to be unnecessary. If users want to download a large number of files from a project, we recommend that they use Globus or include zip files for your data files. However, if you include zip files you should include the unzipped files in your project as well. If you wish to make your data easy to download, it is best to aggregate small individual files into a smaller number of larger files when feasible.
Q: Should I publish raw data?
A: Raw data is that which comes directly from the recording instruments (camera, apps, sensors, scanners, etc.). When raw data is corrected, calibrated, reviewed, edited, or post-processed in any way for publication, it is called curated. Some researchers want to publish their raw data as well as their curated data; if this is your case, consider why it is necessary to publish both sets, and how another researcher would use it. Always clarify whether your data is raw or curated in the description or in a readme file, and use applicable methods to review the data for errors before publishing.
Q: I will publish a large collection of images. What do I need to consider?
A: Be selective with the images you choose to publish. Make sure they have a purpose and are illustrative of a process or a function. Use file tags to describe them. If the images include team members make sure they are comfortable with making their images public. If images include people that have been affected by the natural hazard, you should procure their authorization to make their pictures public.
Q: What type of Data projects can be published in DesignSafe?
A: We have multiple data models and you may publish project types as "Experimental", "Simulation", "Hybrid Simulation", "Field Research" and "Other". Using the "Field Research" data model, you can publish both Engineering/Geosciences collections as well as Social Sciences collections. Stand-alone reports, presentations, software and white papers, as well as datasets that do not fit with the rest of the project types can be published in the project type "Other".
Q: How should I select data to be published in a project?
A: While right now there is no limit to the amount of files that can be published in DesignSafe, the comprehension and reuse potential of the data should be important considerations when selecting what data can be published. This goes with the possibility to clearly describe the data and establish and document its completeness and validity. For all project types, you have the option to select a subset of the files uploaded to My Project that you wish to publish without the need to delete them from the Working Directory.
Q: What should I consider before publishing Jupyter Notebooks?
A: Please refer to our Jupyter User Guide document to find information on how to publish a Jupyter Notebook.
Organizing & Describing Your Dataset¶
Q: How should I organize the data files to be published in a project? A: For each type of project publication, the best way to organize your data is to map them to the organizational schema provided by the data models available for each research type (simulation, experimental, hybrid simulation and field research). These models were designed by experts and represent the main data and documentation components required for others to understand and reuse your dataset.
Q: Can I organize my data files into a hierarchy of folders in DesignSafe?
A: DesignSafe offers methods for categorizing (organizing) and tagging (describing) your files. To enhance organization and description of large and complex projects, users can group files in folders. However, it is always best to avoid overly nesting because browsing through an extensive folder hierarchy on the web is slower than on your local computer. So to improve the user experience, you should try to use the smallest number of nested folders necessary. Instead, you may use categories, descriptions, and tags to indicate what the groupings are. This provides a method for users to identify and search your files efficiently.
Q: How should I describe the dataset organization in a project type "Other"?
A: In project type Other you will be able to tag individual files for ease of data understandability and reuse. If you publish many files and need to organize them in folders, we suggest providing a description of the organizational structure and naming convention that you use in your dataset in a "readme" file or a report. This file can simply be a text file or pdf file.
Q: Why do you require a report/readme in all of your data publications?
A: The "Experimental", "Simulation", "Hybrid Simulation", and "Field Research" project types provide a representation of the structure of the datasets. Still, you may need to clarify the meaning of the fields of your datasets, the functions of your files and their naming convention, the way you decided to organize them, or describe other reuse characteristics of your data. Providing a report/readme file and/or a data dictionary associated with your data is an ideal way to express this information.
Q: How can I provide more contextual information about my published dataset?
A: To enhance the knowledge surrounding your dataset, you can use the "Related Work" field at the project level to point to web-pages, publications, or datasets that are published within or outside DesignSafe and that you consider relevant to point to in your publication. For example, you may point to a separate published project in DesignSafe, or provide the title and DOI of an article that relates to your data. You may also use the description fields in the data model to include specific parameters or facts that you want to highlight (e.g. wind speed during a hurricane, earthquake magnitude, damage types, etc.). Adding tags, both from a controlled list available or by including a custom one, helps other users to find the files that they need within the data landing page.
Q: How can I convey the quality of my data publication?
A: Data quality, as entailed by the metadata, concerns the completeness of the data documentation and the validity and integrity of the data content. Following DesignSafe curation and documentation best practices, as well as the onboarding instructions on the curation and publication interfaces, and adding a data report or data dictionary enables publishing a complete dataset that others will understand. In addition, in the documentation and/or data description, it is important to clarify the processes conducted to assure the completeness and validity of the data content.
Q: I have another published work that is related to the project I am now planning to publish. How can I relate them?
A: On the project landing page under Edit Project there is a "Related Work" field where you have the option to include one or more associated projects and publications to your current project. Here, you can provide the title as well as a link to that project or publication. This link can be a DOI or a URL for any content found inside or outside of DesignSafe. For DOIs, please make sure you are adding the entire DOI address starting with "http" to correctly link the webpage to the related project.
Publishing¶
Q: Which license is appropriate for my publication?
A: Licenses indicate the conditions in which you, as a data creator, want the data to be used by others. Due to the variety of resources published in DesignSafe, we provide four different types of open licenses. These cover datasets, software, materials with intellectual property rights, and the different ways in which you want your work to be attributed. You can find relevant information under licensing here: https://www.designsafe-ci.org/rw/user-guides/data-publication-guidelines/.
Q: What is a DOI?
A: A Digital Object Identifier (DOI) is a unique alphanumeric string assigned by a registration agency (the International DOI Foundation) to identify a resource and provide a persistent link to its location on the Internet. You can find a registered resource by its DOI using the "Resolve a DOI Name" function at: http://www.doi.org/. In addition, you may find the citation information for that DOI in DataCite at https://search.datacite.org/.
Q: What is the relation between a DOI and a data citation?
A: The DOI is a component of a citation for a work that is stored online. Therefore, it provides access to the permanent URL and the cited resource.
Q: I have multiple experiments/simulations/missions to publish under one project. How should I do it?
A: Projects with multiple experiments/simulations/missions (publication units) can be published sequentially over a large period of time. After one publication unit is completed, you may resume uploading files and will be able to publish another unit within the same project. Each may have different authors and will receive individual DOIs.
Q: If the project type is "Experimental"/ "Simulation"/ "Field Research", how can I assign relevant authors to each experiment/simulation/mission?
A: While creating experiments/simulations/missions, you have the option to assign authors to each one. Additionally, after successfully creating the publication, you can click on "Add (Experiment/Simulation/Mission)" on the Curation Directory page and then edit the authors and their order within the corresponding experiment/simulation/mission found in the inventory list.
Q: How can I control the order of the authors for the published project and its citation?
A: In the publication pipeline under "Order Authors" you will be able to arrange the order of authors for each publication using the arrow icons on the screen. This author order will be used in the citation that includes the DOI.
Q: How can I give credit to DesignSafe?
A: Please include the citation of the marker paper in the references/bibliography section of your publication. This is more effective than you providing in-text acknowledgements.
Rathje, E., Dawson, C. Padgett, J.E., Pinelli, J.-P., Stanzione, D., Adair, A., Arduino, P., Brandenberg, S.J., Cockerill, T., Dey, C., Esteva, M., Haan, Jr., F.L., Hanlon, M., Kareem, A., Lowes, L., Mock, S., and Mosqueda, G. 2017. "DesignSafe: A New Cyberinfrastructure for Natural Hazards Engineering," ASCE Natural Hazards Review, doi:10.1061/(ASCE)NH.1527-6996.0000246.
Data Reuse¶
Q: How can I contribute to the reuse of data?
A: Datasets take a lot of work to produce; they are important research products. By creating a complete, clean, and clearly described data publication you are already inviting others to use and cite your data. Always cite your datasets and those of others that you have reused in the reference section of your papers using the citation language and DOI provided on DesignSafe, and encourage your peers and students to do the same. If you use social media or a presentation platform to talk about your research, always include the proper citation and DOI on your materials (ppts, abstracts, emails, etc.). Note that a researcher does not actually need to reuse a dataset to cite it, but rather may cite a dataset to reference something of note in the dataset (e.g., how it was collected, its uniqueness, etc.). This is similar to the process of citing other papers.
Q: How do I cite a dataset in a paper?
A: A dataset is cited using the same format used to cite a journal article or a conference proceeding in the reference section of a paper. Conveniently, you should use the citation language and DOI provided by DesignSafe in the data publication’s landing page.
Q: I reuse data from other sources in my project. How should I credit the data creators in my publication?
A: Frequently you reuse data from other sources in your research and sometimes you even want to re-publish it; it is important to make sure if and how you can do so. In addition, it is always good practice to give credit to the data creators. Please be aware of the following:
-
Be aware of the reused data original license and conditions of usage. The license will specify if and how you can modify, distribute, and cite the reused data.
-
If permitted you may also republish the reused data. This is feasible when the reused dataset is not very large. Else see 3 below.
-
If you reuse data from other sources in your experiments or in your field research, you can point to it from the Referenced Data Title box so others can know about its provenance.
-
In projects type Other, you can point to the reused data from the Related Work box.
-
If you have reused images from other sources (online, databases, publications, etc.), be aware that they may have copyrights. We recommend using the following instructions for how to cite them:
Q: Are there any conditions regarding the usage of data published in DesignSafe? A: Yes, users that download and reuse data agree to the Data Usage conditions published here: These conditions outline the responsibilities of and expectations for data usage including aspects of data licensing, citation, privacy and confidentiality, and data quality.
Policies¶
DesignSafe Data Depot Repository Mission and History¶
Mission¶
The Data Depot Repository (DDR) is the platform for curation and publication of datasets generated in the course of natural hazards research. The DDR is an open access data repository that enables data producers to safely store, share, organize, and describe research data, towards permanent publication, distribution and impact evaluation. The DDR allows data consumers to discover, search for, access, and reuse published data in an effort to accelerate research discovery. The DDR is one component of the DesignSafe cyberinfrastructure, which represents a comprehensive research environment that provides cloud-based tools to manage, analyze, understand, and publish critical data for research to understand the impacts of natural hazards. DesignSafe is part of the NSF-supported Natural Hazards Engineering Research Infrastructure (NHERI), and aligns with its mission to provide the natural hazards research community with open access, shared-use scholarship, education, and community resources aimed at supporting civil infrastructure prior to, during, and following natural disasters. However, DesignSafe also supports the broader natural hazards research community that extends beyond the NHERI network.
History¶
The DDR has been in operation since 2016 and is currently supported by NSF through 2025. The DDR preserves natural hazards research data published since its inception in 2016, and also provides access to legacy data dating from about 2005. These legacy data were generated as part of the NSF-supported Network for Earthquake Engineering Simulation (NEES), a predecessor to NHERI. Legacy data and metadata belonging to NEES were transferred to the DDR for continuous preservation and access. View the published NEES data here.
Community¶
The DDR serves the broader natural hazards research community both as data producers and consumers. This research community includes, but is not limited to, the facilities that make up NHERI network - for which we are the designated data repository. We work with each component of the NHERI network to meet the requirements and commitments of their distinct research focus and functions. As the only repository for open natural hazards research data, we welcome data produced in other national and international facilities and organizations. At large, the repository serves a broad national and international audience of natural hazard researchers, students, practitioners, policy makers, as well as the general public.
Governance¶
Policies for the DDR are driven by the Natural Hazards (NH) scientific community and informed by best practices in library and information sciences. The DDR operates under the leadership of the DesignSafe Management Team (DSMT), who establishes and updates policies, evaluates and recommends best practices, oversees its technical development, and prioritizes activities. The broad organizational structure under which the DDR operates is here.
Repository Team¶
An interdisciplinary repository team (RT) carries out ongoing design, development and day-to-day operations, gathering requirements and discussing solutions through formal monthly and bi-weekly meetings with the NHERI community and maintaining regular communications with members of the network, including monthly meetings with the Experimental Facilities, RAPID, and CONVERGE staff. Based on these fluid communications, the RT designs functionalities, researches and develops best-practices, and implements agreed-upon solutions. The figure below shows the current formation of the RT, including their expertise.

Formal mechanisms are in place for external evaluators to gather feedback and conduct structured assessments, in the form of usability studies and yearly user surveys, to ensure that the repository is meeting the community’s expectations and needs. To track development the DDR curator meets every other week with the DesignSafe PI and with the head of the development team. All DDR activities are reported to the National Science Foundation on a quarterly and annual basis in terms of quantitative and qualitative progress.
Community Norms for DDR¶
Within the broader conditions of use for DesignSafe we have established a set of Community Norms specific for DDR which have to be agreed upon at the point of registering an account on the platform. These norms, highlighting our existing policies, are the following:
Users who either publish and use data in DDR must abide by both the TACC Acceptable Use Policy and the DesignSafe Terms of Use.
For users curating and publishing data in DDR:¶
- Users understand that their data submissions to the DDR should follow our Data Policies and our Curation and Publication Best Practices to the best of their ability.
- Users agree to use DDR to publish only open access data, which they must document in a manner that does not hinder the ability of other users to reuse or reproduce it.
- Users publishing or reusing data of others in their data publications must properly cite the datasets in accordance with the Joint Declaration of Data Citation Principles using the fields provided in the DDR interface.
- Users agree to provide all the needed licenses and permissions to make data available for archiving and for reuse by others.
- Users publishing human subjects data should abide by our Protected Data Best Practices.
- Using DDR to publish data is entirely voluntary. None of these terms supersede any prior contractual obligations to confidentiality or proprietary information the user may have with third parties; thus, the user is entirely responsible for what they upload or share with DDR. .
- Publications that do not fall within these norms may be removed.
For users using data published in DDR:¶
- Users accessing and using DDR data agree to the following Data Use Agreement.
- Users agree to use DDR resources in accessing and reusing open access data in ways that respect the licenses established in the publications.
- Users agree to properly cite the datasets they use in their works in accordance with the Joint Declaration of Data Citation Principles using the citations provided in the published datasets landing pages.
- We reserve the right to ask users to suspend their use of DDR should we receive complaints or note violations of these Community Norms.
Data Collections Development¶
Data Types¶
We accept engineering datasets, as well as social and behavioural sciences datasets, derived from research conducted in the context of natural hazards. In the area of engineering the primary focus is on data generated through simulation, hybrid simulation, experimental and field research methods regarding the impacts of wind, earthquake, and storm surge hazards. We also accept data reports, publications of Jupyter notebooks, code, scripts, lectures, and learning materials. In social and behavioural sciences (SBE), accepted datasets encompass the study of the human dimensions of hazards and disasters. As the field and the expertise of the community evolves we have expanded our focus to include datasets related to COVID-19, Fire Hazards, and Sustainable Material Management.
Users that deposit data that does not correspond to the accepted types will be alerted when possible prior to publication so they can remove their data from DDR, and will not be allowed to publish it. If a dataset non-compliant with the Collections Development policy gets published with a corresponding DOI, we will contact the authors and work with them to remove the data and leave a tombstone explaining why the data is not available. Curators review both in process and published data on a monthly basis. In both cases we will work with the authors to find an adequate repository for their dataset.
Data Size¶
Researchers in the natural hazards community generate very large datasets during large-scale experiments, simulations, and field research projects. At the moment the DDR does not pose limitations on the amount of data to be published, but we do recommend to be selective and publish data that is relevant to a project completeness and is adequately described for reuse. Our Data Curation Best Practices include recommendations to achieve a quality data publication. We are observing trends in relation to sizes and subsequent data reuse of these products, which will inform if and how we will implement data size publication limit policies.
Data Formats¶
We do not pose file format restrictions. The natural hazards research community utilizes diverse research methods to generate and record data in both open and proprietary formats, and there is continual update of equipment used in the field. We do encourage our users to convert to open formats when possible. The DDR follows the Library of Congress Recommended Format Statement and has guidance in place to convert proprietary formats to open formats for long term preservation; see our Accepted and Recommended Data Formats for more information. However, conversion can present challenges; Matlab, for example, allows saving complex data structures, yet not all of the files stored can be converted to a csv or a text file without losing some clarity and simplicity for handling and reusing the data. In addition, some proprietary formats such as jpeg, and excel have been considered standards for research and teaching for the last two decades. In attention to these reasons, we allow users to publish the data in both proprietary and open formats. Through our Fedora repository we keep file format identification information of all the datasets stored in DDR.
Data Curation¶
Data curation involves the organization, description, representation, permanent publication, and preservation of datasets in compliance with community best practices and FAIR data principles. In the DDR, data curation is a joint responsibility between the researchers that generate data and the DDR team. Researchers understand better the logic and functions of the datasets they create, and our team's role is to help them make these datasets FAIR-compliant.
Our goal is to enable researchers to curate their data from the beginning of a research project and turn it into publications through interactive pipelines and consultation with data curators. The DDR has and continues to invest efforts in developing and testing curation and publication pipelines based on data models designed with input from the NHERI community.
Data Management Plan¶
For natural hazards researchers submitting proposals to the NSF using any of the NHERI network facilities/resources, or alternative facilities/resources, we developed Data Management guidelines that explain how to use the DDR for data curation and publication. See Data Management Plan at: https://www.designsafe-ci.org/rw/user-guides/ and https://converge.colorado.edu/data/data-management
Data Models¶
To facilitate data curation of the diverse and large datasets generated in the fields associated with natural hazards, we worked with experts in natural hazards research to develop five data models that encompass the following types of datasets: experimental, simulation, field research, hybrid simulation, and other data products (See: 10.3390/publications7030051; 10.2218/ijdc.v13i1.661) as well as lists of specialized vocabulary. Based on the Core Scientific Metadata Model, these data models were designed considering the community's research practices and workflows, the need for documenting these processes (provenance), and using terms common to the field. The models highlight the structure and components of natural hazards research projects across time, tests, geographical locations, provenance, and instrumentation. Researchers in our community have presented on the design, implementation and use of these models broadly.
In the DDR web interface the data models are implemented as interactive functions with instructions that guide the researchers through the curation and publication tasks. As researchers move through the tion pipelines, the interactive features reinforce data and metadata completeness and thus the quality of the publication. The process will not move forward if requirements for metadata are not in place (See Metadata in Best Practices), or if key files are missing.
Metadata¶
Up to date, there is no standard metadata schema to describe natural hazards data. In DDR we follow a combination of standard metadata schemas and expert-contributed vocabularies to help users describe and find data.
Embedded in the DDR data models are categories and terms as metadata elements that experts in the NHERI network contributed and deemed important for data explainability and reuse. Categories reflect the structure and components of the research dataset, and the terms describe these components. The structure and components of the published datasets are represented on the dataset landing pages and through the Data Diagram presented for each dataset.
Due to variations in their research methods, researchers may not need all the categories and terms available to describe and represent their datasets. However, we have identified a core set of metadata that allows proper data representation, explainability, and citation. These sets of core metadata are shown for each data model in our Metadata Requirements in Best Practices.
To further describe datasets, the curation interface offers the possibility to add both predefined and custom file tags. Predefined file tags are specialized terms provided by the natural hazard community; their use is optional, but highly recommended. The lists of tags are evolving for each data model, continuing to be expanded, updated, and corrected as we gather feedback and observe how researchers use them in their publications.
For purposes of metadata exchange and interoperability, the elements and tags in the data models are mapped to widely-used, standardized metadata schemas. These are: Dublin Core for description of the dataset project, DDI (Data Documentation Initiative) for social science data, DataCite for DOI assignment and citation, and PROV-O to record the structure of the dataset. Metadata mapping is substantiated as the data is ingested into Fedora. Users can download the standardized metadata in the publications landing page.
Metadata and Data Quality¶
The diversity and quantity of research methods, instruments, and data formats in natural hazards research is vast and highly specialized. For this reason, we conceive of data quality as a collaboration between the researchers and the DDR. In consultation with the larger NHERI network we are continuously observing and defining best practices that emerge from our community's understanding and standards.
We address data quality from a variety of perspectives:
Metadata quality: Metadata is fundamental to data explainability and reuse. To support metadata quality we provide onboarding descriptions of all metadata elements, indicate which ones are required, and suggest how to complete them. Requirements for core metadata elements are automatically reinforced within the publication pipeline and the dataset will not be published if those are not fulfilled. Metadata can be accessed by users in standardized formats on the projects’ landing pages.
Data content quality: Different groups in the NHERI network have developed benchmarks and guidelines for data quality assurance, including StEER, CONVERGE and RAPID. In turn, each NHERI Experimental Facility has methods and criteria in place for ensuring and assessing data quality during and after experiments are conducted. Most of the data curated and published along NHERI guidelines in the DDR are related to peer-reviewed research projects and papers, speaking to the relevance and standards of their design and outputs. Still, the community acknowledges that for very large datasets the opportunity for detailed quality assessment emerges after publication, as data are analyzed and turned into knowledge. Because work in many projects continues after publication, both for the data producers and reusers, the community has the opportunity to version datasets.
Data completeness and representation: We understand data completeness as the presence of all relevant files that enable reproducibility, understandability, and therefore reuse. This may include readme files, data dictionaries and data reports, as well as data files. The DDR complies with data completeness by recommending and requesting users to include required data to fullfill the data model required categories indispensable for a publication understandibility and reuse. During the publication process the system verifies that those categories have data assigned to them.The Data Diagram on the landing page reflects which relevant data categories are present in each publication. A similar process happens for metadata during the publication pipeline; metadata is automatically vetted against the research community’s Metadata Requirements before moving on to receive a DOI for persistent identification.
We also support citation best practices for datasets reused in our publications. When users reuse data from other sources in their data projects, they have the opportunity to include them in the metadata through the Related Works and Referenced Data fields.
Data publications review: Once a month, data curators meet to review new publications. These reviews show us how the community is using and understanding the models, and allows verifying the overall quality of the data publications. When we identify curation problems (e.g. insufficient or unclear descriptions, file or category misplacement, etc.) that could not be automatically detected, we contact the researchers and work on solving these issues. Based on the feedback, users have the possibility to amend/improve their descriptions and to version their datasets (See amends and version control).
Curation and Publication Assistance ¶
We believe that researchers are best prepared to tell the story of their projects through their data publications; our role is to enable them to communicate their research to the public by providing flexible and easy to use curation resources and guidance that abide by publication best practices. To support researchers organizing, categorizing and describing their data, we provide interactive pipelines with onboarding instructions, different modes of training and documentation, and one-on-one help.
Interactive pipelines: The DDR interface is designed to facilitate large scale data curation and publication through interactive step-by-step capabilities aided by onboarding instructions. This includes the possibility to categorize and tag multiple files in relation to the data models, and to establish relations between categories via diagrams that are intuitive to data producers and easy to understand for data consumers. Onboarding instructions including vocabulary definitions, suggestions for best practices, availability of controlled terms, and automated quality control checks are in place.
One-on-one support: We hold virtual office hours twice a week during which a curator is available for real-time consulting with individuals and teams. Other virtual consulting times can be scheduled on demand. Users can also submit Help tickets, which are answered within 24 hours, as well as send emails to the curators. Users also communicate with curatorial staff via the DesignSafe Slack channel. The curatorial staff includes a natural hazards engineer, a data librarian, and a USEX specialist. Furthermore, developers are on call to assist when needed.
Guidance on Best Practices: Curatorial staff prepares guides and video tutorials, including special training materials for Undergraduate Research Experience students and for Graduate Students working at Experimental Facilities.
Webinars by Researchers: Various researchers in our community contribute to our curation and publication efforts by conducting webinars in which they relay their data curation and publication experiences. Some examples are webinars on curation and publication of hybrid simulations, field research and social sciences datasets.
Data Publication and Usage¶
Protected Data¶
Protected data are information subject to regulation under relevant privacy and data protection laws, such as HIPAA, FERPA and FISMA, as well as human subjects data containing Personally Identifiable Information (PII) and data involving vulnerable populations and or containing sensitive information.
Publishing protected data in the DDR involves complying with the requirements, norms, and procedures approved by the data producers Institutional Review Board (IRB) or equivalent body regarding human subjects data storage and publication, and managing direct and indirect identifiers in accordance with accepted means of data de-identification. In the DDR protected data issues are considered at the onset of the curation and publication process and before storing data. Researchers working with protected data in DDR have the possibility to communicate this to the curation team when they select a project type in DDR and the curator gets in touch with them to discuss options and procedures.
Unless approved by an IRB, most forms of protected data cannot be published in DesignSafe. No direct identifiers and only up to three indirect identifiers are allowed in published datasets. However, data containing PII can be published in the DDR with proper consent from the subject(s) and documentation of that consent in the project's IRB paperwork. In all publications involving human subjects, researchers should include and publish their IRB documentation showing the agreement.
If as a consequence of data de-identification the data looses meaning, it is possible to publish a description of the data, the corresponding IRB documents, the data instruents if applicable, and obtain a DOI and a citation for the dataset. In this case, the dataset will show as with Restricted Access. In addition, authors should include information of how to reach them in order to gain access or discuss more information about the dataset. The responsibility to maintain the protected dataset in compliance with the IRB comitements and for the long term will lie on the authors, and they can use TACC's Protected Data Services if they need to. For more information on how to manage this case see our Protected Data Best Practices.
It is the user’s responsibility to adhere to these policies and the procedures and standards of their IRB or other equivalent institution, and DesignSafe will not be held liable for any violations of these terms regarding improper publication of protected data. User uploads that we are notified of that violate this policy may be removed from the DDR with or without notice, and the user may be asked to suspend their use of the DDR and other DesignSafe resources. We may also contact the user’s IRB and/or other respective institution with any cases of violation, which could incur in an active audit (See 24) of the research project, so users should review their institution’s policies regarding publishing with protected data before using DesignSafe and DDR.
For any data not subject to IRB oversight but may still contain PII, such as Google Earth images containing images of people not studied in the scope of the research project, we recommend blocking out or blurring any information that could be considered PII before publishing the data in the DDR. We still invite any researchers that are interested in seeing the raw data to contact the PI of the research project to try and attain that. See our Protected Data Best Practices for information on how to manage protected data in DDR.
Subsequent Publishing¶
Attending to the needs expressed by the community, we enable the possibility to publish data and other products subsequently within a project, each with a DOI. This arises from the longitudinal and/or tiered structure of some research projects such as experiments and field research missions which happen at different time periods, may involve multiple distinct teams, have the need to publish different types of materials or to release information promptly after a natural hazards event and later publish related products. Subsequent publishing is enabled in My Project interface where users and teams manage and curate their active data throughout their projects' lifecycle.
Timely Data Publication ¶
Although no firm deadline requirements are specified for data publishing, as an NSF-funded platform we expect researchers to publish in a timely manner, so we provide recommended timelines for publishing different types of research data in our Timely Data Publication Best Practices.
Peer Review¶
Users that need to submit their data for revision prior to publishing and assigning a DOI have the opportunity to do so by: a) adding reviewers to their My Project, when there is no need for annonymous review, or b) by contacting the DesignSafe data curator through a Help ticket to obtain a Public Accessibility Data Delay (See below). Note that the data must be fully curated prior to requesting a Public Accessibility Delay.
Public Accessibility Delay ¶
Many researchers request a DOI for their data before it is made publicly available to include in papers submitted to journals for review. In order to assign a DOI in the DDR, the data has to be curated and ready to be published. Once the DOI is in place, we provide services to researchers with such commitments to delay the public accessibility of their data publication in the DDR, i.e. to make the user’s data publication, via their assigned DOI, not web indexable through DataCote and or not publicly available in DDR's data browser until the corresponding paper is published in a journal, or for up to one year after the data is deposited. The logic behind this policy is that once a DOI has been assigned, it will inevitably be published, so this delay can be used to provide reviewers access to a data publication before it is broadly distributed. Note that data should be fully curated, and that while not broadly it will be eventually indexed by search engines. Users that need to amend/correct their publications will be able to do so via version control. See our Data Delay Best Practices for more information on obtaining a public accessibility delay.
Data Licenses¶
DDR provides users with 5 licensing options to accommodate the variety of research outputs generated and how researchers in this community want to be attributed. The following licenses were selected after discussions within our community. In general, DDR users are keen about sharing their data openly but expect attribution. In addition to data, our community issues reports, survey instruments, presentations, learning materials, and code. The licenses are: Creative Commons Attribution (CC-BY 4.0), Creative Commons Public Domain Dedication (CC-0 1.0), Open Data Commons Attribution (ODC-BY 1.0), Open Data Commons Public Domain Dedication (ODC-PPDL 1.0), and GNU General Public License (GNU-GPL 3). During the publication process users have the option of selecting one license per publication with a DOI. More specifications of these license options and the works they can be applied to can be found in Licensing Best Practices.
DDR also requires that users reusing data from others in their projects do so in compliance with the terms of the data original license.
The expectations of DDR and the responsibilities of users in relation to the application and compliance with licenses are included in the DesignSafe Terms of Use, the Data Usage Agreement, and the Data Publication Agreement. As clearly stated in those documents, in the event that we note or are notified that the licencing policies and best practices are not followed, we will notify the user of the infringement and may cancel their DesignSafe account.
Data Citation¶
DDR abides by and promotes the Joint Declaration of Data Citation Principles amongst its users.
We encourage and facilitate researchers using data from the DDR to cite it using the DOI and citation language available in the datasets landing page. The DOI relies on the DataCite schema for citation and accurate access.
For users publishing data in DDR, we enable referencing works and or data reused in their projects. For this we provide two fields, Related Work and Referenced Data, for citing data and works in their data publication landing page.
The expectations of DDR and the responsibilities of users in relation to the application and compliance with data citation are included in the DesignSafe Terms of Use, the Data Usage Agreement, and the Data Publication Agreement. As clearly stated in those documents, in the event that we note or are notified that citation policies and best practices are not followed, we will notify the user of the infringement and may cancel their DesignSafe account.
However, given that it is not feasible to know with certainty if users comply with data citation, our approach is to educate our community by reinforcing citation in a positive way. For this we implement outreach strategies to stimulate data citation. Through diverse documentation, FAQs webinars, and via emails, we regularly train our users on data citation best practices. And, by tracking and publishing information about the impact and science contributions of the works they publish citing the data that they use, we demonstrate the value of data reuse and further stimulate publishing and citing data.
Data Publication Agreement¶
This agreement is read and has to be accepted by the user prior to publishing a dataset.
This submission represents my original work and meets the policies and requirements established by the DesignSafe Policies and Best Practices. I grant the Data Depot Repository (DDR) all required permissions and licenses to make the work I publish in the DDR available for archiving and continued access. These permissions include allowing DesignSafe to:
- Disseminate the content in a variety of distribution formats according to the DDR Policies and Best Practices.
- Promote and advertise the content publicly in DesignSafe.
- Store, translate, copy, or re-format files in any way to ensure its future preservation and accessibility,
- Improve usability and/or protect respondent confidentiality.
- Exchange and or incorporate metadata or documentation in the content into public access catalogues.
- Transfer data, metadata with respective DOI to other institution for long-term accessibility if needed for continuos access.
I understand the type of license I choose to distribute my data, and I guarantee that I am entitled to grant the rights contained in them. I agree that when this submission is made public with a unique digital object identifier (DOI), this will result in a publication that cannot be changed. If the dataset requires revision, a new version of the data publication will be published under the same DOI.
I warrant that I am lawfully entitled and have full authority to license the content submitted, as described in this agreement. None of the above supersedes any prior contractual obligations with third parties that require any information to be kept confidential.
If applicable, I warrant that I am following the IRB agreements in place for my research and following Protected Data Best Practices.
I understand that the DDR does not approve data publications before they are posted; therefore, I am solely responsible for the submission, publication, and all possible confidentiality/privacy issues that may arise from the publication.
Data Usage Agreement¶
Users who access, preview, download or reuse data and metadata from the DesignSafe Data Depot Repository (DDR) agree to the following policies. If these policies are not followed, we will notify the user of the infringement and may cancel their DesignSafe account.
- Use of the data includes, but is not limited to, viewing parts or the whole of the content; comparing with data or content in other datasets; verifying research results and using any part of the content in other projects, publications, or other related work products.
- Users will not use the data in any way prohibited by applicable laws, distribution licenses, and permissions explicit in the data publication landing pages.
- The data are provided “as is,” and its use is at the users' risk. While the DDR promotes data and metadata quality, the data authors and publishers do not guarantee that:
- the materials are accurate, complete, reliable or correct;
- any defects or errors will be corrected;
- the materials and accompanying files are free of viruses or other harmful components; or
- the results of using the data will meet the user’s requirements.
- Use of data in the DDR abides by the DesignSafe Privacy Policy.
- Users are responsible for abiding by the restrictions outlined by the data author in their publications' landing pages and by the DDR in this agreement, but they are not responsible for any restrictions not otherwise explicitly described here or in the landing pages.
- Users will not obtain personal information associated with DDR data that results in directly or indirectly identifying research subjects, individuals, or organizations with the aid of other information acquired elsewhere.
- Users will not in any event hold the DDR or the data authors liable for any and all losses, costs, expenses, or damages arising from use of DDR data or any other violation of this agreement, including infringement of licenses, intellectual property rights, and other rights of people or entities contained in the data.
- We do not gather IP addresses about public users that preview or download files from the DDR.
- Our system logs file actions completed by registered users in the DDR including previewing, downloading or copying published data to My Data or My Projects. We only use this information in aggregate for metrics purposes and do not link it to the user’s identity.
Amends and Version Control¶
Users can amend and version their data publications. Since the DDR came online, we have helped users correct and or improve the metadata applied to their datasets after publication. Most requests involve improving the text of the descriptions, changing the order of the authors, and adding references of papers publised using the data in the project; users also required the possibility to version their datasets. Our amends and version control policy derives from meeting our users needs.
Changes allowed during amends are:
- Adding Related Works such as a paper they published after the data.
- Correct typos and or improve the abstract and the keyword list.
- Correct or add an award.
- Change the order of the authors.
If users need to add or delete files or change the content of the files, they have the opportunity to version their data publication. The following are the
- Versions will have the same DOI, and the title will indicate the version number. The decision to maintain the same DOI was agreed upon by our community to facilitate DOI management to data publishers and users.
- Users will be able to view all existing versions in the publication's landing page.
- The DOI will always resolve in the latest version of the publication.
- Versions are documented by data publishers so other users understand what changed and why. The documentation is publicly displayed
Documentation of versions requires including the name of the file/s changed, removed or added, and identifying within which category they are located. We include guidance on how to document versions within the curation and publication onboarding instruction.
The Fedora repository manages all amends and versions so there is a record of all changes. Version number is passed to DataCite as metadata.
More information about the reasons for amends and versioning are in Publication Best Practices.
Leave Data Feedback¶
Users can click a “Leave Feedback” button on the projects’ landing pages to provide comments on any publication. This feedback is forwarded to the curation team for any needed actions, including contacting the authors. In addition, it is possible for users to message the authors directly as their contact information is available via the authors field in the publication landing pages. We encourage users to provide constructive feedback and suggest themes they may want to discuss about the publication in our Leave Data Feedback Best Practices
Data Impact¶
We understand data impact as a strategy that includes complementary efforts at the crossroads of data discoverability, usage metrics, and scholarly communications.
Search Engine Optimization (SEO)
We have in place SEO methods to enhance the web visibility of the data publications. To increase discoverability and indexing of our publications we follow guidance from Google Search Console and Google Data Search.
Data Usage Metrics
Our metrics follow the Make your Data Count Counter Code of Practice for Research Data.
Below are the definitions for each metric:
File Preview: Examining data in the portal such as clicking on a file name brings up a modal window that allows previewing files. Not all document types can be previewed. Among those that can are: text, spreadsheets, graphics and code files. (example extensions: .txt, .doc, .docx, .csv, .xlsx, .pdf, .jpg, .m, .ipynb). Those that can't include binary executables, MATLAB containers, compressed files, and video (eg. .bin, .mat, .zip, .tar, mp4, .mov).
File Download: Copying a file to the machine the user is running on, or to a storage device that machine has access to. This can be done by ticking the checkbox next to a document and selecting "Download" at the top of the project page. With documents that can be previewed, clicking "Download" at the top of the preview modal window has the same effect. Downloads are counted per project and per individual files. We also consider counts of copying a file from the published project to the user's My data, My projects, or to Tools and applications in DesignSafe or one of the connected spaces (Box, Dropbox, Google Drive). Tick the checkbox next to a document and select "Copy" at the top of the project page.
File Requests: Total file downloads + total file previews.
Project Downloads: Total downloads of a compressed entire project to a user's machine.
We report the metrics in the publications landing pages. To provide context to the metrics, we indicate the total amount of files in each publication.
We started counting since May 17, 2021. We update the reports on a monthly basis and we report data metrics to NSF every quarter. Currently we are in the process of formatting the reports to participate in the Make your Data Count initiative.
Data Vignettes
Since 2020 we conduct Data Reuse Vignettes. For this, we identify published papers and interview researchers that have reused data published in DDR. In this context, reuse means that researchers are using data published by others for purposes different than those intended by the data creators. During the interviews we use a semi-structured questionnaire to discuss the academic relevance of the research, the ease of access to the data in DDR, and the understandability of the data publication in relation to metadata and documentation clarity and completeness. We feature the data stories on the DesignSafe website and use the feedback to make changes and to design new reuse strategies. The methodology used in this project was presented at the International Qualitative and Quantitative Methods in Libraries 2020 International Conference . See Perspectives on Data Reuse from the Field of Natural Hazards Engineering.
Data Awards
In 2021 we launched the first Data Publishing Award to encourage excellence in data publication and to stimulate reuse. Data publications are nominated by our user community based on contribution to scientific advancement and curation
Data Preservation¶
Data preservation encompasses diverse activities carried out by all the stakeholders involved in the lifecycle of data, from data management planning to data curation, publication and long-term archiving. Once data is submitted to the Data Depot Repository (DDR,) we have functionalities and Guidance in place to address the long-term preservation of the submitted data.
The DDR has been operational since 2016 and is currently supported by the NSF from October 1st, 2020 through September 30, 2025. During this award period, the DDR will continue to preserve the natural hazards research data published since its inception, as well as supporting preservation of and access to legacy data and the accompanying metadata from the Network for Earthquake Engineering Simulation (NEES), a NHERI predecessor, dating from 2005. The legacy data comprising 33 TB, 5.1 million files,2 and their metadata was transferred to DesignSafe in 2016 as part of the conditions of the original grant. See NEES data here.
Data in the (DDR) is preserved according to state-of-the art digital library standards and best practices. DesignSafe is implemented within the reliable, secure, and scalable storage infrastructure at the Texas Advanced Computing Center (TACC), with 20 years of experience and innovation in High Performance Computing. TACC is currently over 20 years old, and TACC and its predecessors have operated a digital data archive continuously since 1986 – currently implemented in the Corral Data Management system and the Ranch tape archive system, with capacity of approximately half an exabyte. Corral and Ranch hold the data for DesignSafe and hundreds of other research data collections. For details about the digital preservation architecture and procedures for DDR go to Data Preservation Best Practices.
Within TACC’s storage infrastructure a Fedora repository, considered a standard for digital libraries, manages the preservation of the published data. Through its functionalities, Fedora assures the authenticity and integrity of the digital objects, manages versioning, identifies file formats, records preservation events as metadata, maintains RDF metadata in accordance to standard schemas, conducts audits, and maintains the relationships between data and metadata for each published research project and its corresponding datasets. Each published dataset in DesignSafe has a Digital Object Identifier, whose maintenance we understand as a firm commitment to data persistence.
While at the moment DDR is committed to preserve data in the format in which it is submitted, we procure the necessary authorizations from users to conduct further preservation actions as well as to transfer the data to other organizations if applicable. These permissions are granted through our Data Publication Agreement, which authors acknowledge and have the choice to agree to at the end of the publication workflow and prior to receiving a DOI for their dataset.
Data sustainability is a continuous effort that DDR accomplishes along with the rest of the NHERI partners. In the natural hazards space, data is central to new advances, which is evidenced by the data reuse record of our community and the following initiatives:
- Data reuse cases: www.designsafe-ci.org/rw/impact-of-data-reuse
- DesignSafe Dataset Awards: www.designsafe-ci.org/community/news/2021/march/dataset-awards
- Data requirements for AI Session at: “Workshop on Artificial Intelligence in Natural Hazards Engineering.” https://doi.org/10.17603/ds2-f1nd-9s05
- Converge Data Ambassadors: https://converge.colorado.edu/data/events/publish-your-data/data-ambassadors
- Identifying Data Guideline Needs for Community and Regional Resilience Modelling Workshop: http://resilience.colostate.edu/files/DATA/Agenda_DATA_20210316.pdf
Continuity of Access¶
As part of the requirements of the current award we have a contingency pan in place to transfer all the DDR data, metadata and corresponding DOIs to a new awardee (should one be selected) without interruption of services and access to data. Fedora has export capabilities for transfer of data and metadata to another repository in a complete and validated fashion. The portability plan is confirmed and updated in the Operations Project Execution Plan that we present anually to the NSF.
In the case in which the NSF and/or the other stakeholders involved in this community decide not to continue the NHERI program or a subsequent data repository, we will continue to preserve the published data and provide access to it through TACC, DesignSafe’s host at the University of Texas at Austin. TACC has formally committed to preserving the data with landing pages and corresponding DOIs indefinitely. TACC has on permanent staff a User Services team as well as curators that will attend users’ requests /and help tickets related to the data. Because TACC is constantly updating its high-performance storage resources and security mechanisms, data will be preserved at the same preservation level that is currently available. Considering that DOIs are supported through the University of Texas Libraries and that the web services and the data reside within TACC’s managed resources, access to data will not be interrupted. Fedora is now part of TACC’s software suite and we will continue its maintenance as our preservation repository. Like with all systems at TACC, we will revisit its versioning and continuity and make decisions based on state-of-the-art practices. Should funding constraints ever make this no longer possible, TACC will continue to keep an archive copy on Ranch (with landing pages on online storage) for as long as TACC remains a viable entity.
Metadata Dictionaries¶
Experimental¶
Below are the minimal amount of elements required to describe the experimental datasets in DesignSafe. The elements represent the structure of the datasets, are useful for data discovery and allow proper citation of the data publication. The tables show the definition of each metadata element and how it maps to a metadata standard such as Dublin Core or Data Documentation Initiative. Elements specific to natural hazards engineering that do not map to a metadata standard were defined by DesignSafe simulation and data requirements team members. All research project types share some basic metadata elements. Those metadata elements are listed in the generic Other Project Type.
| Metadata Term | Definition | Metadata Standard Mapping |
|---|---|---|
| Experiment |
A scientific process undertaken to make a discovery, test a hypothesis, or demonstrate a known fact. |
|
|
Experiment Report |
Written accounts made to convey information about an entire project or experiment. |
|
|
DOI |
Digital Object Identifier. An unambiguous reference to the resource within a given context. |
|
|
Experiment Title |
A name given to the resource. |
|
|
Author |
An entity primarily responsible for making the resource. |
|
|
Experiment Description |
An account of the resource. |
|
|
Date of Publication |
A point or period of time associated with an event - publication- in the lifecycle of the resource. |
|
|
Date of Experiment |
A point or period of time associated with an event - experiment - in the lifecycle of the resource. |
|
|
Experimental Facility |
The site where an experiment is planned, built, instrumented, and conducted. |
|
|
Experiment Type |
The nature or genre of the resource (experiment). |
|
|
Model Configuration |
Files describing the design and layout of what is being tested (some call this a specimen). |
|
|
Sensor Information |
Files about the sensor instrumentation used in a model configuration to conduct one or more event. |
DesignSafe |
|
Event |
Files from unique occurrences during which data are generated. |
|
|
Analysis |
Tables, graphs, visualizations, Jupyter Notebooks, or other representations of the results. |
DesignSafe |
|
Analysis Title |
A name given to the resource. |
|
|
Analysis Description |
An account of the resource. |
|
|
Referenced Data |
A related resource that is referenced, cited, or otherwise pointed to by the described resource. |
Simulation¶
Below are the minimal amount of elements required to describe the simulation datasets in DesignSafe. The elements represent the structure of the datasets, are useful for data discovery and allow proper citation of the data publication. The tables show the definition of each metadata element and how it maps to a metadata standard such as Dublin Core or Data Documentation Initiative. Elements specific to natural hazards engineering that do not map to a metadata standard were defined by DesignSafe simulation and data requirements team members. All research project types share some basic metadata elements. Those metadata elements are listed in the generic Other Project Type.
|
Metadata Term |
Definition |
Metadata Standard Mapping |
|---|---|---|
|
Simulation |
The imitation of the operation of a real-world process or system over time. |
|
|
Simulation Title |
A name given to the resource |
|
DOI |
Digital Object Identifier. An unambiguous reference to the resource within a given context. |
|
|
Author |
The creator of a resource. |
|
|
Simulation Description |
An account of the resource. |
|
|
Simulation Type |
The nature or genre of the resource (simulation). |
|
|
Simulation Model |
Files and/or information describing the design, geometry, and/or code of a simulation. |
|
|
Simulation Input |
Files containing the parameters of the simulation. |
DesignSafe |
|
Simulation Output |
Files containing the results of a simulation. |
DesignSafe |
|
Referenced Data |
A related resource that is referenced, cited, or otherwise pointed to by the described resource. |
|
|
Simulation Report |
Written accounts made to convey information about an entire project or simulation. |
|
|
Analysis |
A computational examination of the data resultant from an experiment, simulation, or hybrid simulation typically as a basis for discussion or interpretation. |
DesignSafe |
|
Analysis Title |
A name given to the resource. |
Hybrid¶
Below are the minimal amount of elements required to describe the hybrid simulation datasets in DesignSafe. The elements represent the structure of the datasets, are useful for data discovery and allow proper citation of the data publication. The tables show the definition of each metadata element and how it maps to a metadata standard such as Dublin Core or Data Documentation Initiative. Elements specific to natural hazards engineering that do not map to a metadata standard were defined by DesignSafe simulation and data requirements team members. All research project types share some basic metadata elements. Those metadata elements are listed in the generic Other Project Type.
|
Metadata Term |
Definition |
Metadata Standard Mapping |
|---|---|---|
|
Hybrid Simulation |
Combines physical and analytical components into a single system under study to evaluate the response of a structure, often under seismic ground motion. |
|
|
Hybrid Simulation Type |
The nature or genre of the resource. |
|
|
Hybrid Simulation Title |
A name given to the resource. |
|
|
Hybrid Simulation Description |
An account of the resource. |
|
DOI |
Digital Object Identifier. An unambiguous reference to the resource within a given context. |
|
|
Author |
The creator of a resource. |
|
|
Global Model |
Files describing the entire structure, loading protocol, and components of the hybrid simulation. |
Data Cite: Model |
|
Global Model Title |
A name given to the resource. |
|
|
Master Simulation Coordinator |
Software files that communicate with the simulation and experimental substructure simultaneously to give commands and receive feedback data. |
DesignSafe |
|
Master Simulation Coordinator Title |
A name given to the resource. |
|
|
Coordinator Output |
Data generated by the master simulation coordinator. |
DesignSafe |
|
Simulation Substructure |
Files and/or information describing the planning and design of the numerical model. |
DesignSafe |
|
Simulation Substructure Title |
A name given to the resource. |
|
|
Experimental Substructure |
A purely numerical representation of a substructure through simulation supported software. |
DesignSafe |
|
Experimental Substructure Title |
A name given to the resource. |
|
|
Experimental Output |
Data generated by the experimental substructure |
DesignSafe |
|
Analysis |
Tables, graphs, visualizations, Jupyter Notebooks, or other representations of the results. |
DesignSafe |
|
Analysis Title |
A name given to the resource. |
|
|
Report |
Written accounts made to convey information about an entire project or hybrid simulation |
Field¶
Below are the minimal amount of elements required to describe the field research datasets in DesignSafe. The elements represent the structure of the datasets, are useful for data discovery and allow proper citation of the data publication. The tables show the definition of each metadata element and how it maps to a metadata standard such as Dublin Core or Data Documentation Initiative. Elements specific to natural hazards engineering that do not map to a metadata standard were defined by DesignSafe simulation and data requirements team members. All research project types share some basic metadata elements. Those metadata elements are listed in the generic Other Project Type.
|
Metadata Term |
Definition |
Metadata Standard Mapping |
|---|---|---|
|
Project Title |
A name given to the resource. |
|
DOI |
Digital Object Identifier. An unambiguous reference to the resource within a given context. |
|
|
Author(s) |
The creator of a resource. |
|
|
Project Type |
The nature or genre of the resource. |
|
|
Field Research Description |
An account of the resource. |
|
|
Natural Hazard Event |
The name given to a natural hazard that occurred in time and space. |
|
|
Natural Hazard Date |
A point or period of time associated with the Natural Hazard event. |
|
|
Natural Hazard Event Location |
A spatial region or named place. |
|
|
Documents Collection |
An aggregation of resources. |
|
|
Referenced Data |
A related resource that is referenced, cited, or otherwise pointed to by the described resource. |
|
|
Mission |
Group collections of data representing: different visits to a site, field teams, field experiments, or research topics (e.g., liquefaction, structural performance, wave inundation, etc.). Some researchers refer to missions using terms such as "time 1", "wave 1", etc. |
DesignSafe |
|
Mission Title |
A name given to the resource. |
|
|
Date(s) of Mission |
A point or period of time associated with the Mission. |
|
|
Mission Site Location |
A spatial region or named place. |
|
|
Mission Description |
An account of the resource. |
|
|
Documents Planning Collection |
Includes instruments, protocols, and different reports (Virtual Recon, Field Assessment, Preliminary Virtual Assessment, etc). These documents are published separately with their own DOI. |
|
|
Data Collector(s) |
The creator of a resource. |
|
|
Collection Description |
An account of the resource |
|
|
Referenced Data |
A related resource that is referenced, cited, or otherwise pointed to by the described resource. |
|
|
Social Sciences Collection |
Groups related data from the social sciences domain. |
|
|
Collection Title |
A name given to the resource. |
|
|
Date(s) of Collection |
A point or period of time associated with the Collection. |
|
|
Unit of Analysis |
A description of who or what is being studied. |
|
|
Mode(s) of Collection |
The procedure/technique of the inquiry used to obtain the data. |
|
|
Sampling Approach(es) |
Methods used to sample the population. |
Data Documentation Initiative: Sample Frame |
|
Sample Size |
The targeted sample size in integer format. |
|
|
Collection Site Location |
A spatial region or named place. |
|
|
Equipment Type |
The special equipment used. |
|
|
Restriction |
Information about who access the resource or an indication of its security status. |
|
|
Referenced Data |
A related resource that is referenced, cited, or otherwise pointed to by the described resource. |
|
|
Engineering/Geosciences Collection |
Groups related data from the engineering/geosciences domain. |
|
|
Equipment Type |
The special equipment used. |
|
|
Observation Type |
The nature or subject of the data collected. |
Other¶
Below are the minimal amount of elements required to describe the other datasets in DesignSafe. The elements represent the structure of the datasets, are useful for data discovery and allow proper citation of the data publication. The tables show the definition of each metadata element and how it maps to a metadata standard such as Dublin Core or Data Documentation Initiative.
|
Metadata Term |
Definition |
Metadata Standard Mapping |
|---|---|---|
|
DOI |
Digital Object Identifier. An unambiguous reference to the resource within a given context. |
|
|
Project Title |
A name given to the resource |
|
|
Author (PIs/Team Members) |
An entity primarily responsible for making the resource. |
|
|
Data Type |
The nature or genre of the resource. |
|
|
Description |
An account of the resource. |
|
|
Publisher |
An entity responsible for making the resource available |
|
|
Date of Publication |
A point or period of time associated with an event - publication - in the lifecycle of the resource. |
|
|
License |
A legal document giving official permission to do something with the resource. |
|
|
Related Works |
A related resource. |
|
|
Awards |
Information about financial support (funding) for the resource being registered. |
|
|
Keywords |
A topic of the resource. |