Jupyter
JupyterHub Guide
DesignSafe provides you access to the Jupyter ecosystem via its JupyterHub. The most popular component of the Jupyter ecosystem is the Jupyter notebook that allows you to create and share documents (i.e., notebooks) that contain code, equations, visualizations, and narrative text. Jupyter notebooks can be used for many research-related tasks including data cleaning and transformation, numerical simulation, statistical modeling, data visualization, and machine learning.
You can access DesignSafe's JupyterHub via the DesignSafe-CI workspace by selecting "Workspace" > "Tools & Applications" > "Analysis" > "Jupyter" > Select "Jupyter" > "Launch" or directly via https://jupyter.designsafe-ci.org. Upon entry you will be prompted to log in using your DesignSafe credentials.
JupyterHub Spawner
If you have not accessed Jupyter previously or if your previous Jupyter session has stopped you will be brought to the JupyterHub Spawner. An image of the JupyterHub Spawner is shown below.
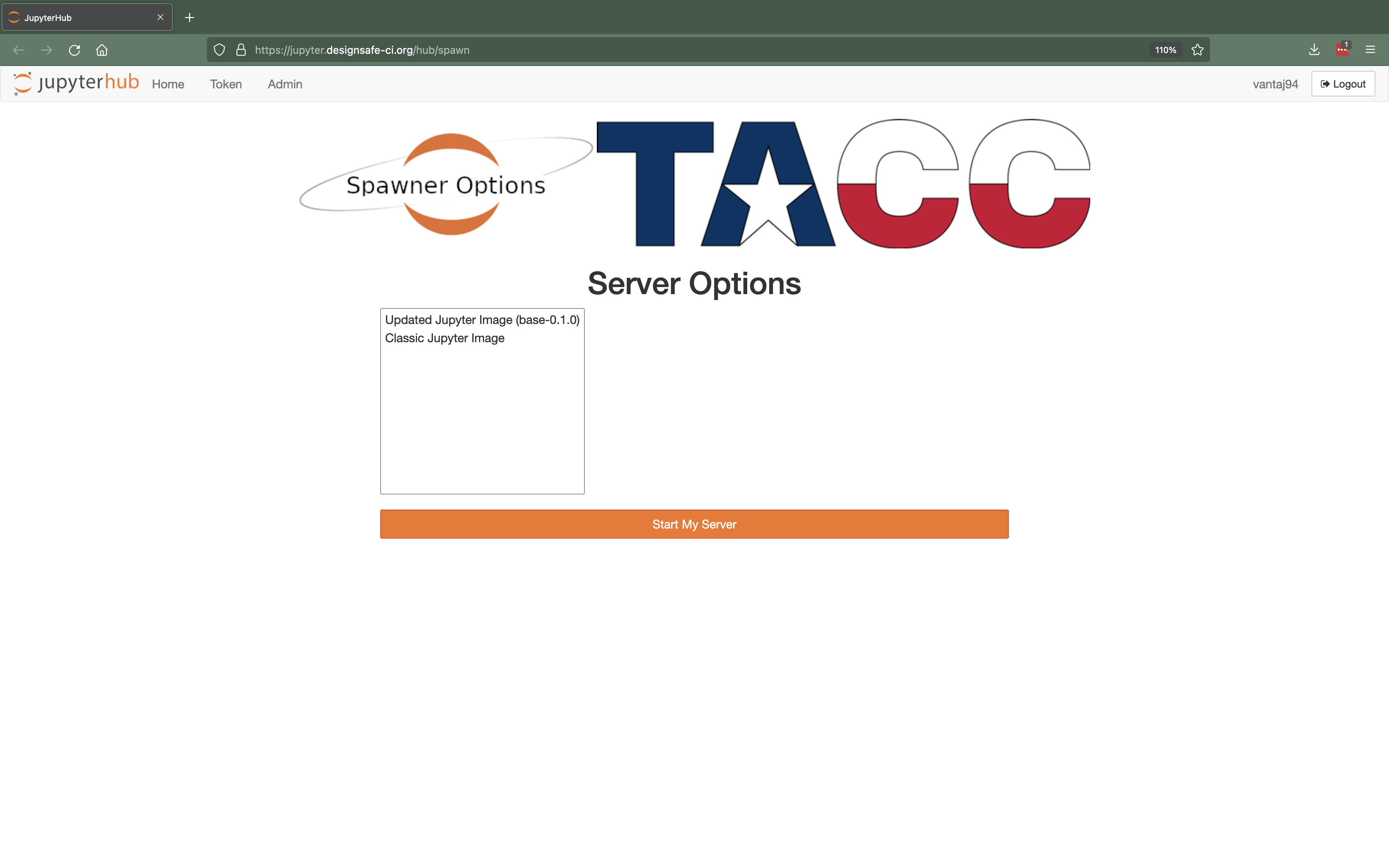 Figure 1. JupyterHub Spawner
Figure 1. JupyterHub Spawner
The JupyterHub Spawner allows you to select from different notebook images available on DesignSafe. Each notebook image provides a unique user-interface complete with various pre-installed system and software-specific packages. There are two notebook images available the Classic Jupyter Image and the Updated Jupyter Image. To use an image, select it from the list and click "Start My Server". The spawner will then prepare and serve you the associated image via your browser. Note that it may take a minute or two for the image to load.
The interface that you see once your image has been served will depend on the image you selected. The two options are the classic JupyterNotebook interface (the default for older images) or the updated JupyterLab interface (the default for newer images). Images of the classic JupyterNotebook Interface and the updated JupyterLab Interface are shown below.
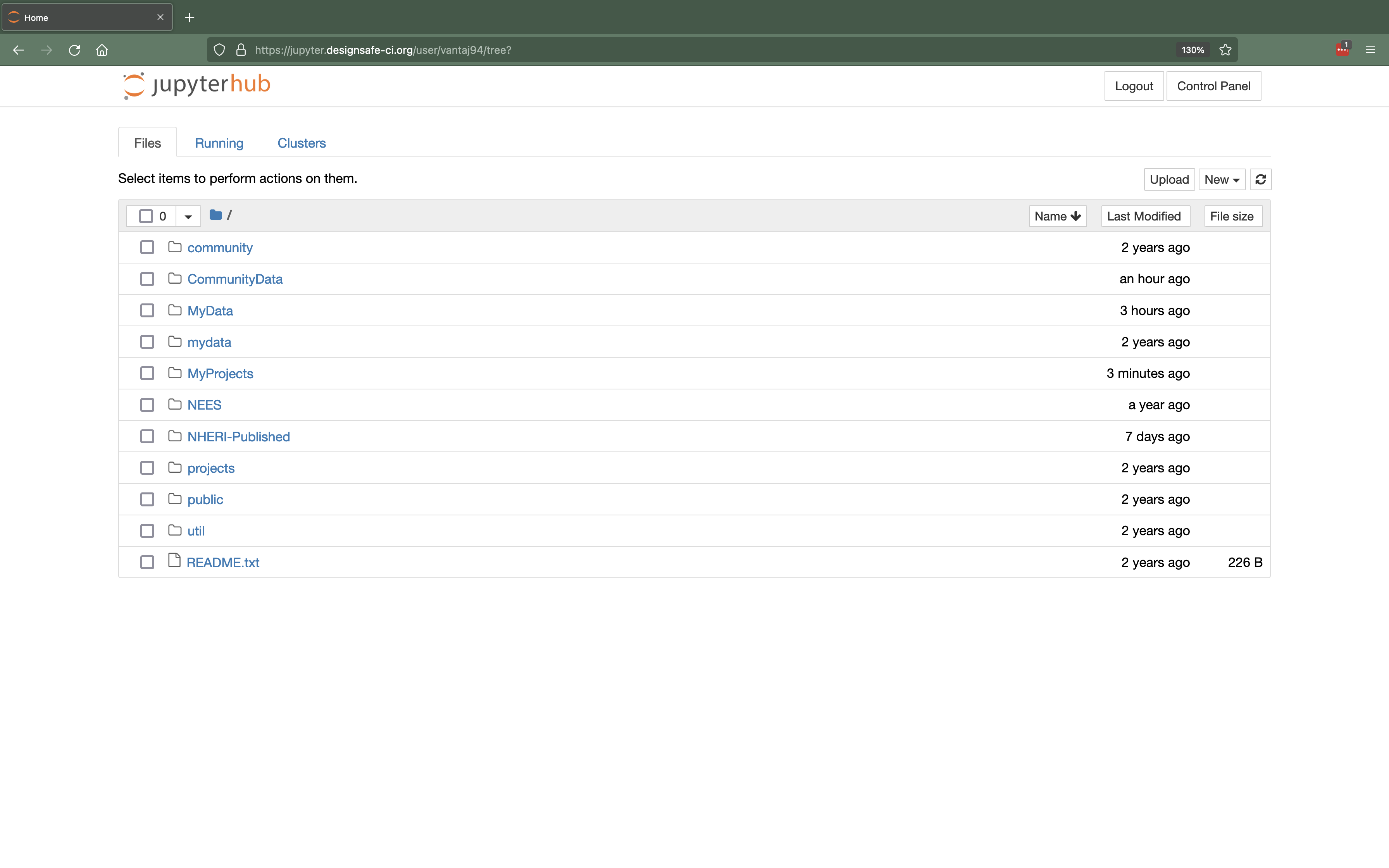 Figure 2. Classic JupyterNotebook Interface
Figure 2. Classic JupyterNotebook Interface
To return to the spawner in the classic JupyterNotebook interface select "Control Panel" > "Stop My Server" > "Start My Server".
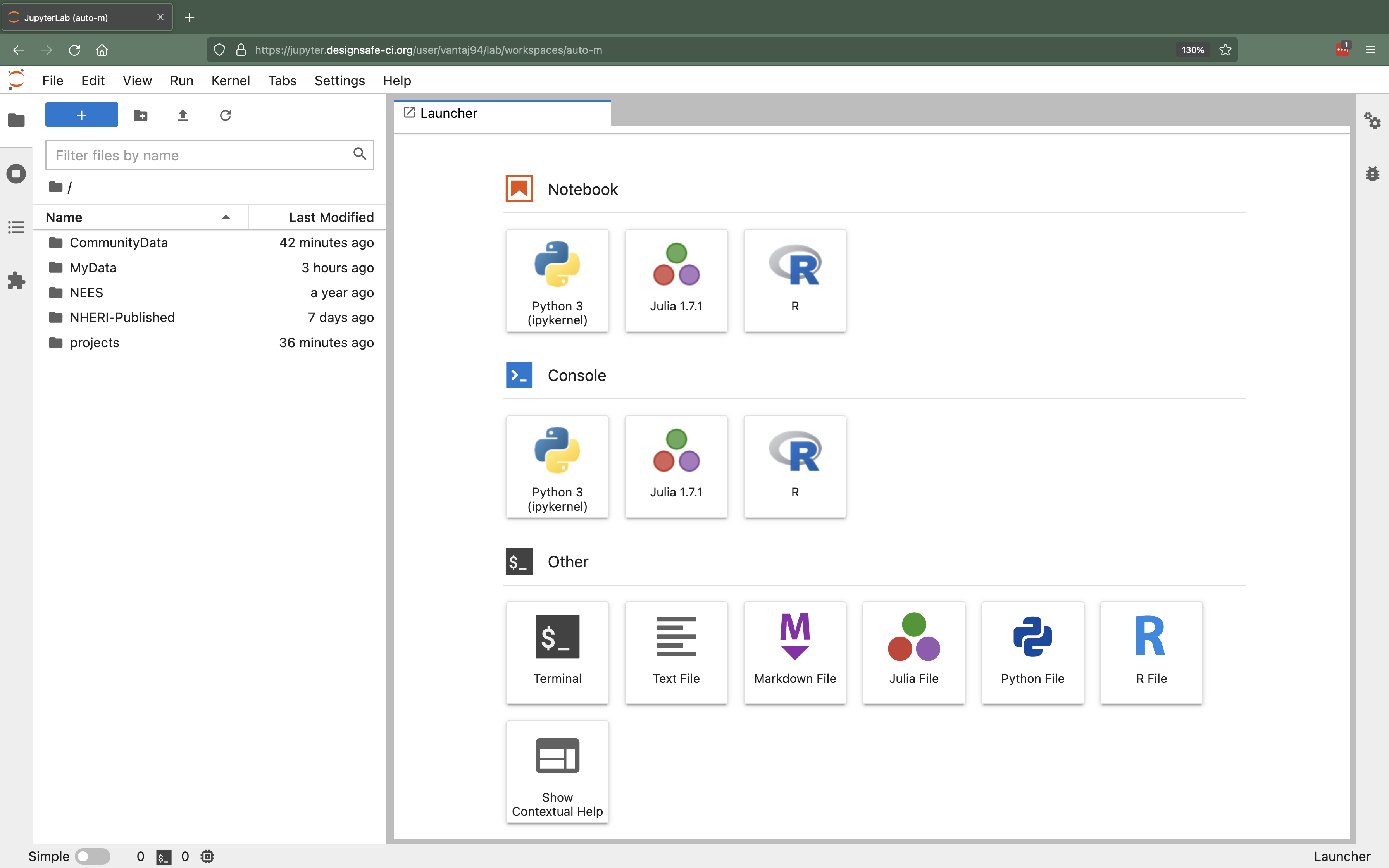 Figure 3. Updated JupyterLab Interface
Figure 3. Updated JupyterLab Interface
To return to the spawner in the updated JupyterNotebook interface select "File" > "Hub Control Panel" > "Stop My Server" > "Start My Server".
Jupyter Notebook Images
As mentioned in the previous section there are two images available for use on DesignSafe the Classic Jupyter Image and the Updated Jupyter Image.
Classic Jupyter Image
The Classic Jupyter Image was the default image prior to March 2022. The image uses JupyterNotebook as its default interface, supplies Python 3.6 as its default Python interpreter, and provides an R kernel. The image comes with many Advanced Package Tool (APT) and Python packages pre-installed. As a result many users will be able to use the image without having to perform custom installations using pip or conda (see section on Installing Packages for details), however this also result in a large image with many interdependent packages that makes adding or upgrading packages difficult.
Updated Jupyter Image
The Updated Jupyter Image was released in March 2022 to replace the Classic Jupyter Image. The image uses JupyterLab as its default interface, supplies Python 3.9 as its default Python interpreter, and provides an R and Julia kernel. The new image provides fewer pre-installed APT and Python packages compared to the Classic Jupyter Image to allow it to remain light and flexible. Small packages that are quick to install can be done so at the top of a notebook via pip or conda (see section on Installing Packages for details). Persistent installations can be created and shared between users using the kernelutility Python package (see section on Installing Packages for details).
Accessing Data from the Data Depot
While using Jupyter on DesignSafe you have access to all your files stored in the Data Depot. The directory "MyData" and "projects" point to the "My Data" and "My Projects" sections of the Data Depot, respectively. Files in "CommunityData", "NEES", and "NHERI-Published" point to the "Community Data", "Published (NEES)", and "Published" sections of the Data Depot, respectively.
In the Classic Jupyter Image you may notice very similarly named directories (e.g., "mydata" and "MyData"). These folders ("mydata", "projects", and "community’") are symlinks for their similarly named counterparts and were added during the development of the Classic Jupyter Image to ensure backwards compatability. You can use either of these directories to access your files, however using the CamelCase directories is preferred. Note that in the Updated Jupyter Image the symlinks have been removed and only one set of directories is provided to present a simplified user experience.
Note that any changes (e.g., edits, deletions, and etcetera) made in Jupyter are immediately reflected in the Data Depot. Importantly, all of your work should be saved within your "MyData" or "projects" directories, changes in all other directories will be lost upon server termination. Stated differently, data is not preserved between Jupyter server sessions except within the "MyData" and "projects" directories.
If you have recently created or been added to a project on DesignSafe, you will need to stop and restart your server to ensure the new project is accessible through the "projects" directory. The general procedure for this is to first return to the JupyterHub spawner (see the JupyterHub Spawner section for instructions) > Log Out > Log In > Start Your Server. Please note that the projects are listed by their project (PRJ) number which can be found next to the project's title when viewing through the Data Depot.
Using Jupyter
Creating a Jupyter Notebook
Creating a new Jupyter notebook is different depending on whether you are using the classic JupyterNotebook interface or the updated JupyterLab interface.
For the classic JupyterNotebook interface select "New" > then select the notebook of your choice for example "Python 3". If you want to run a notebook using a different kernel for example Python 2, R, or Bash you can do so using a similar approach. Note that the notebook will be created in the directory that you are currently viewing, so be sure to navigate into "MyData" or "projects" before creating a new notebook to ensure your changes will be saved.
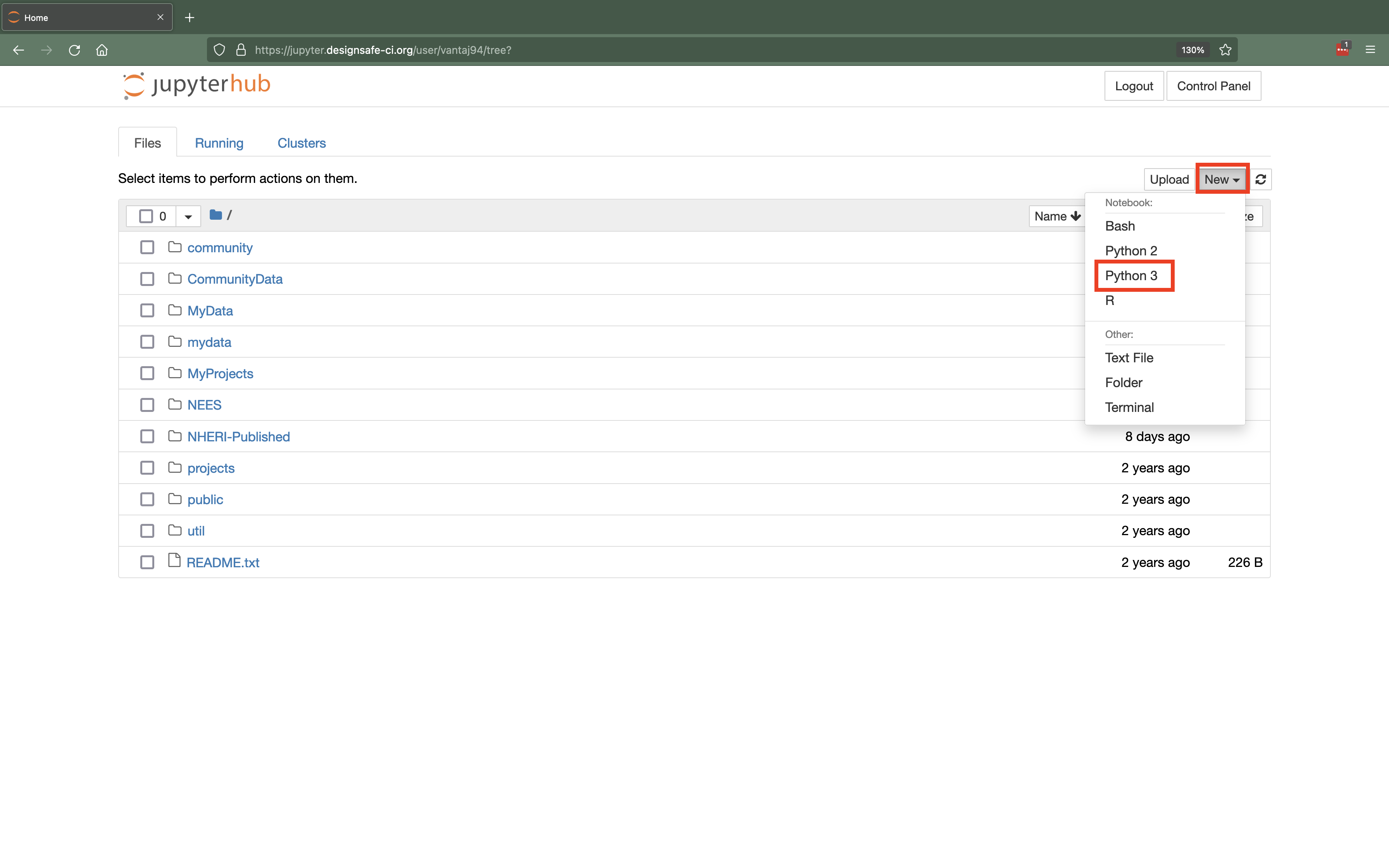 Figure 4.
Figure 4.
For the updated JupyterLab interface select "+" to open the launcher > then select the notebook of your choice for example "Python 3 (ipykernel)". If you want to run a notebook using a different kernel for example Julia or R you can do so using a similar approach. Note that the notebook will be created in the directory that you are currently viewing, so be sure to navigate into "MyData" or "projects" before creating a new notebook to ensure your changes will be saved.
 Figure 5.
Figure 5.
Ending your Jupyter Session
The computational resource on which DesignSafe's JupyterHub operates is a shared resource meaning that the computational resources you use will be taken from a shared pool. To ensure that these resources are available to as many researchers as possible we ask that users stop your Jupyter server, thereby freeing up those resources for others, when you are no longer using Jupyter. To shut down your server in the classic JupyterNotebook interface select "Control Panel" > "Stop My Server" > "Log Out" and in the updated JupyterLab interface select "File" > "Hub Control Panel" > "Stop My Server" > "Log Out".
Server Information
Each Jupyter session is served through an Ubuntu-based Docker image and distributed across a Kubernetes cluster located at the Texas Advanced Computing Center (TACC). To ensure Jupyter is available to as many researchers as possible each server has limited computational power (4 cores) and memory (10 GB).
High Performance Computing (HPC) Job Submission through Jupyter
For greater computational power, you can use agavepy, a Python interface to TAPIS, to submit jobs to TACC's high performacne computing systems (e.g., Frontera) directly through Jupyter. Existing applications avaialble through DesignSafe include OpenSees, SWbatch, ADCIRC and others. For more information, please watch the following webinar on leveraging DesignSafe using TAPIS here.
Installing Packages
Each Juptyer image contains some pre-installed system and software-specific packages. This section will focus on Python packages, however packages for the Julia and R kernels can also be installed using their respective syntax. System-related packages, those requiring sudo privaledges, cannot be installed by users directly, but may be requested by submitting a ticket. Requests for system-related packages will be approved on a case-by-case basis. Requests should include a clear and compeling justification for why the system-related package will be of benefit to the natural hazards community.
There are two approaches for installing Python packages the first is via effemoral user installations and the second is via custom user-defined kernels. Note that only the former is availabe in the Classic Jupyter Image whereas both are available in the Updated Jupyter Image.
Ephemeral User Installations
Ephemoral or temporary user installations of Python packages is the preferrred approach when the number of required packages is small and/or when those installations can be done relatively quickly (i.e., in a few minutes). To perform the installation you can either open a Jupyter "Terminal" and use standard pip or conda syntax (e.g., pip install tensorflow) or use the "!", "%pip", or "%conda" line magics (e.g., !pip install tensorflow) to execute pip in a subshell in Jupyter directly. Note in the Classic Jupyter Image you will also need to add the "--user" flag to ensure a user-based installation (e.g., pip install tensorflow --user). After the installation completes you will need to restart your Jupyter notebook by going to "Kernel" > "Restart and Clear All Output" for Python to be able to see the recently installed package. The second approach of doing the installation at the top of the notebook is generally preferred to using the Terminal as it allows you to document the dependencies required for your work. Importantly, installations using this procedure are ephemoral and will survive only as long as your Jupyter session. As soon as your Jupyter session ends, your server will be cleaned up, and all installations will be destroyed. For the ability to create persistent installations see the next section on Custom User-Defined Kernels.
Custom User-Defined Kernels
The objective of custom user-defined kernels is to allow users to build, customize, and share entire Python kernels to enable highly-customized Jupyter workflows and greater scientific reproducability. Each kernel includes their own Python interpreter and any number of user-selected Python packages installed via pip or conda. By being able to create and share their Python kernels, resarchers are able to easily create, share, and publish their development enviroments alongside their software avoiding any potential issue related to the environment and the dreaded "It works on my machine" issue.
User-defined kernels are supported in the Updated Jupyter Image using the kernelutility Python package. To get started you will need to install the kernelutility which you can do using pip (e.g., in Jupyter "!pip install kernelutility", do not forget to restart your notebook after the installation is complete for Python to be able to see the new installation). To start using the kernelutility, run "from kernelutility import kernelset". Importing the kernelset will restore any kernels you created previously and allow you to manage your kernels via Python. The kernelset instance of the KernelSet class has four basic methods: create - that allows you to create new kernels, destroy - that allows you destroy previously created kernels, add - that allows you to add an existing kernel from a specified path by making a local copy, and remove - that allows you to remove a previously added or created kernel. Note that add is similar to destroy except that it does not clean up the kernel's files on disk such that it can be added again later if desired. Once you have created or added a new kernel those will become selectable alongside the base Python 3, Julia, and R kernels in the Launcher tab. Note that you can create as many kernels as you like to manage your various projects and their dependencies on DeisgnSafe. When you shutdown your server your user-defined kernels will not be immediately visible on restart, to activate them all you need to do is open a Jupyter notebook and run "from kernelutility import kernelset". If you do not see your kernels reappear wait a few seconds, refresh your browser, and return to the Launcher tab.
If you have any issues using DesignSafe's JupyterHub, please create a ticket (https://designsafe-ci.org/help).
DesignSafe HPC Jupyter Guide
On DesignSafe web portal, three versions of Jupyter have been created, including Jupyter, Jupyter Lab HPC (CPU) and Jupyter Lab HPC (GPU). Jupyter will be run on a virtual machine, while Jupyter Lab HPC (CPU) and Jupyter Lab HPC (GPU) will be run on CPU and GPU nodes on Frontera, respectively. In particular, the Jupyter Lab HPC (GPU) will be run on Frontera's NVIDIA RTX GPU nodes that have the best performance, and many commonly used Python packages for AI/ML applications have been pre-installed, including TensorFlow and PyTorch.
| Application | Pro | Con |
|---|---|---|
| Jupyter | No wait; No maximum job runtime limit; Sufficient memory for data processing purpose |
Low performance for AI/ML jobs; Need to install Python packages every time |
| Jupyter Lab HPC (CPU) | More memory and faster than Jupyter; No need to reinstall Python packages once they have been installed; Excellent capability for data processing and parallel computing using 56 cores. |
Queue exists, longer wait time may be needed; Slower than Jupyter Lab HPC (GPU) for deep learning jobs; Maximum job runtime is 48 hours |
| Jupyter Lab HPC (GPU) | Four GPUs in total, best performance for AI/ML jobs; Many commonly used Python packages for AI/ML applications have been pre-installed, including TensorFlow and PyTorch |
Queue exists, longer wait time may be needed; Maximum job runtime is 48 hours |
Note: When using the Jupyter Lab HPC (CPU) and Jupyter Lab HPC (GPU), you need to place all your files/data/codes/Jupyter Notebooks inside the HPCWork folder. This can be done on DesignSafe Data Depot page without submitting any jobs.
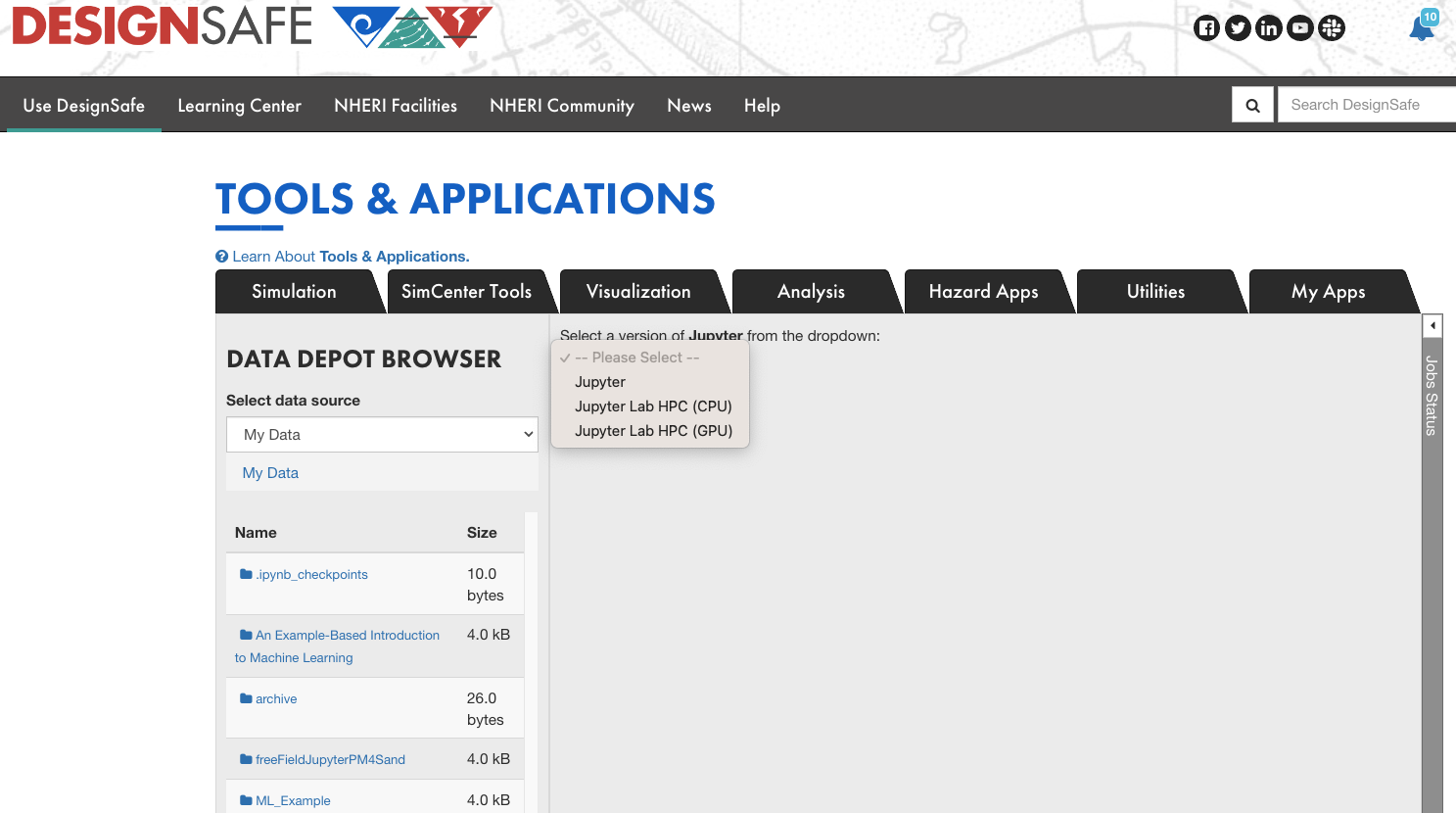
Launch the Jupyter Lab HPC (GPU)
-
Go to DesignSafe website and sign in to your DesignSage account. Then click "Use DesignSafe" > "Tools & Applications" > "Analysis" > "Jupyter" and select "Jupyter Lab HPC (GPU)".
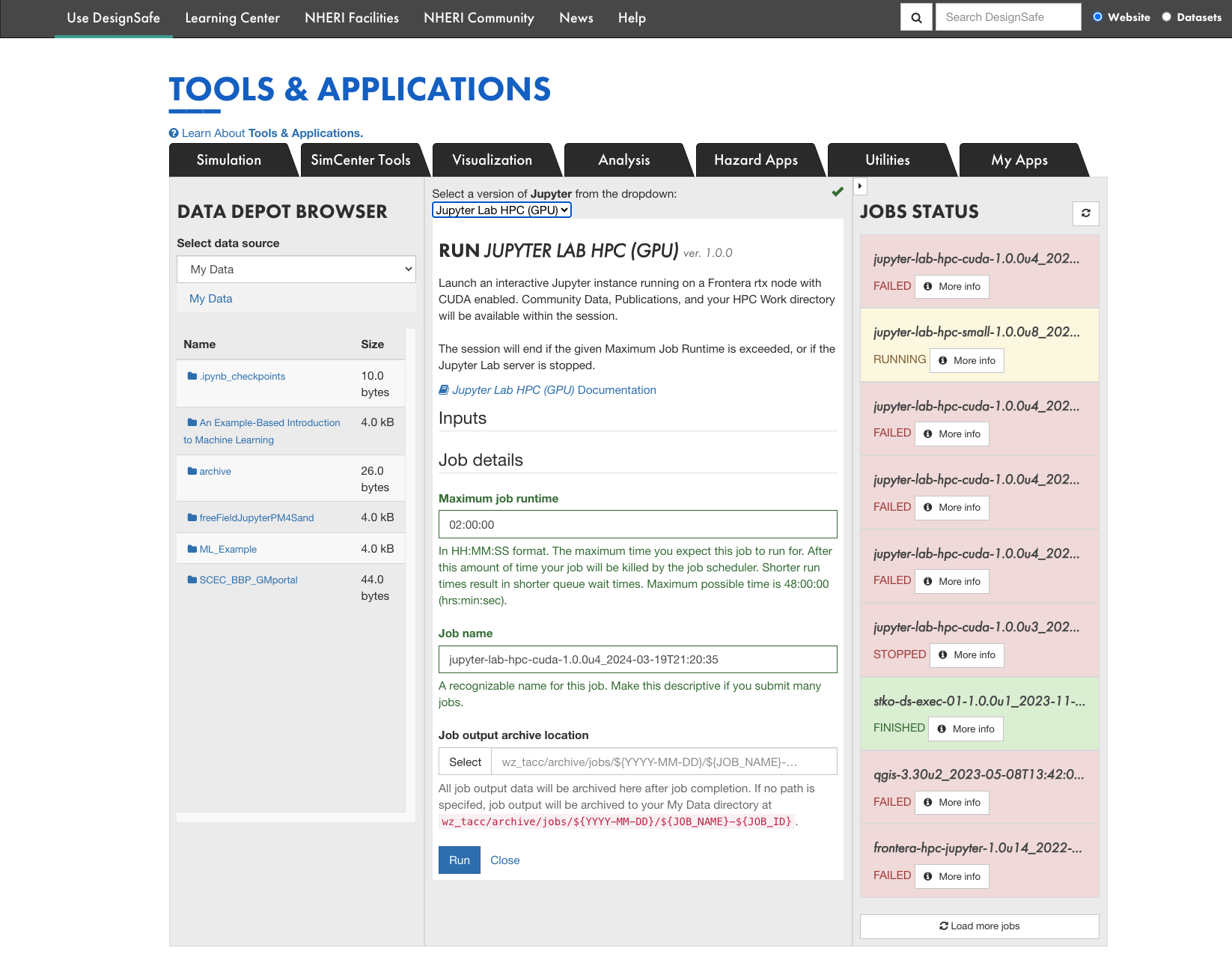
-
Once define your maximum Job runtime (no more than 48 hours) and Job name, click the "Run" buttton so the job will be submitted. Then you can monitor your job status on the right column.
-
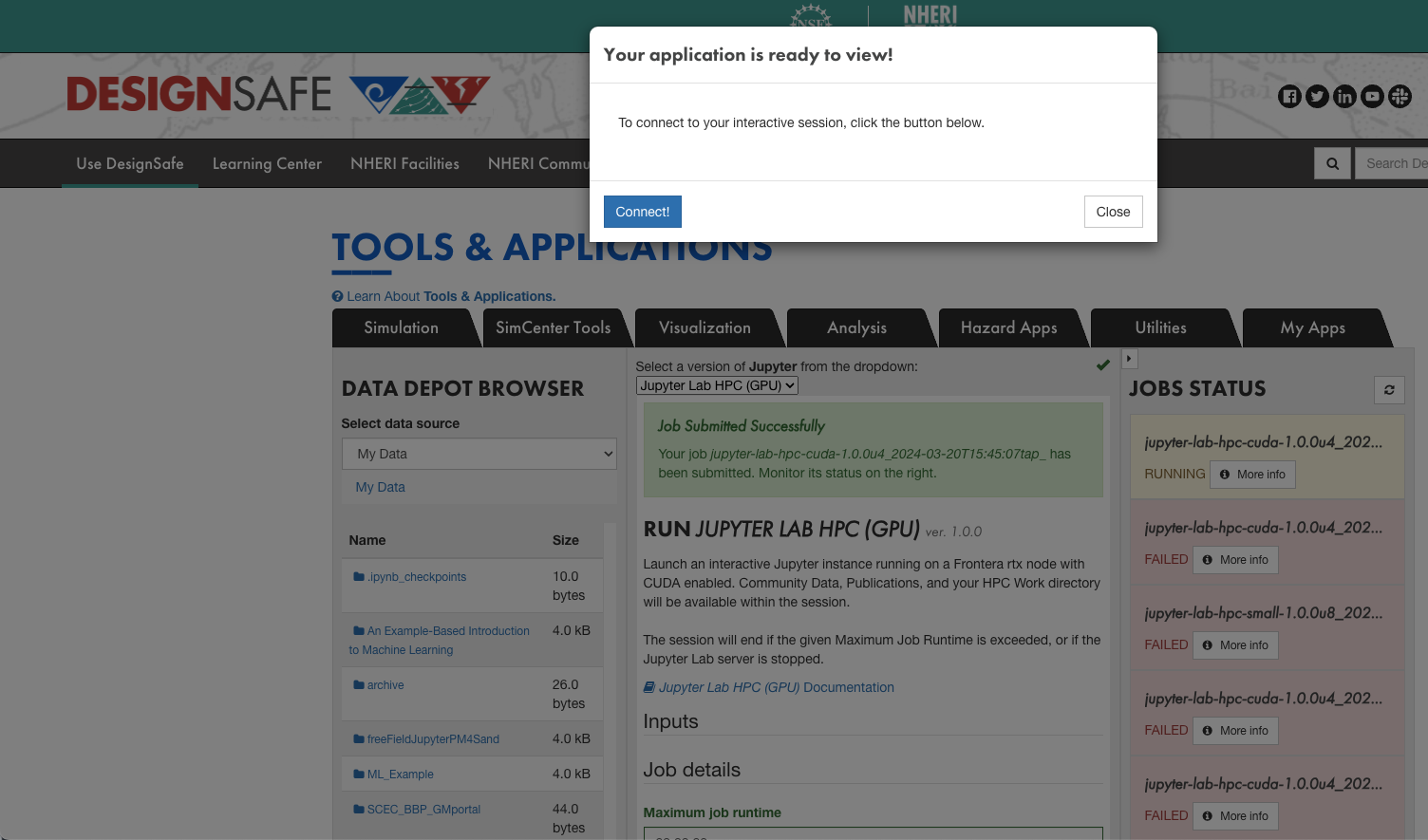
Once your job starts, the Job Status bar will show status as "RUNNING" and a small window will pop up. Then click the "CONNECT!" button to connect to your interactive session, i.e., JupyterLab.
Launch the Jupyter Notebook
-
Navigate to the "HPCWork" folder. You need to place all your
data/codes/Jupyter Notebooksinside this folder.
-
Click on the
Python 3 (ipykernel)button on the right to launch a new Jupyter Notebook. In this example, a Jupyter NotebookTest.ipynbwas created. As seen, the PyTorch has been pre-installed and a total of four GPUs have been recognized. By typingpip list, you can view all the Python packages that have been pre-installed, including many popular ones, such as matplotlib, numpy, scipy, TensorFlow, PyTorch, etc.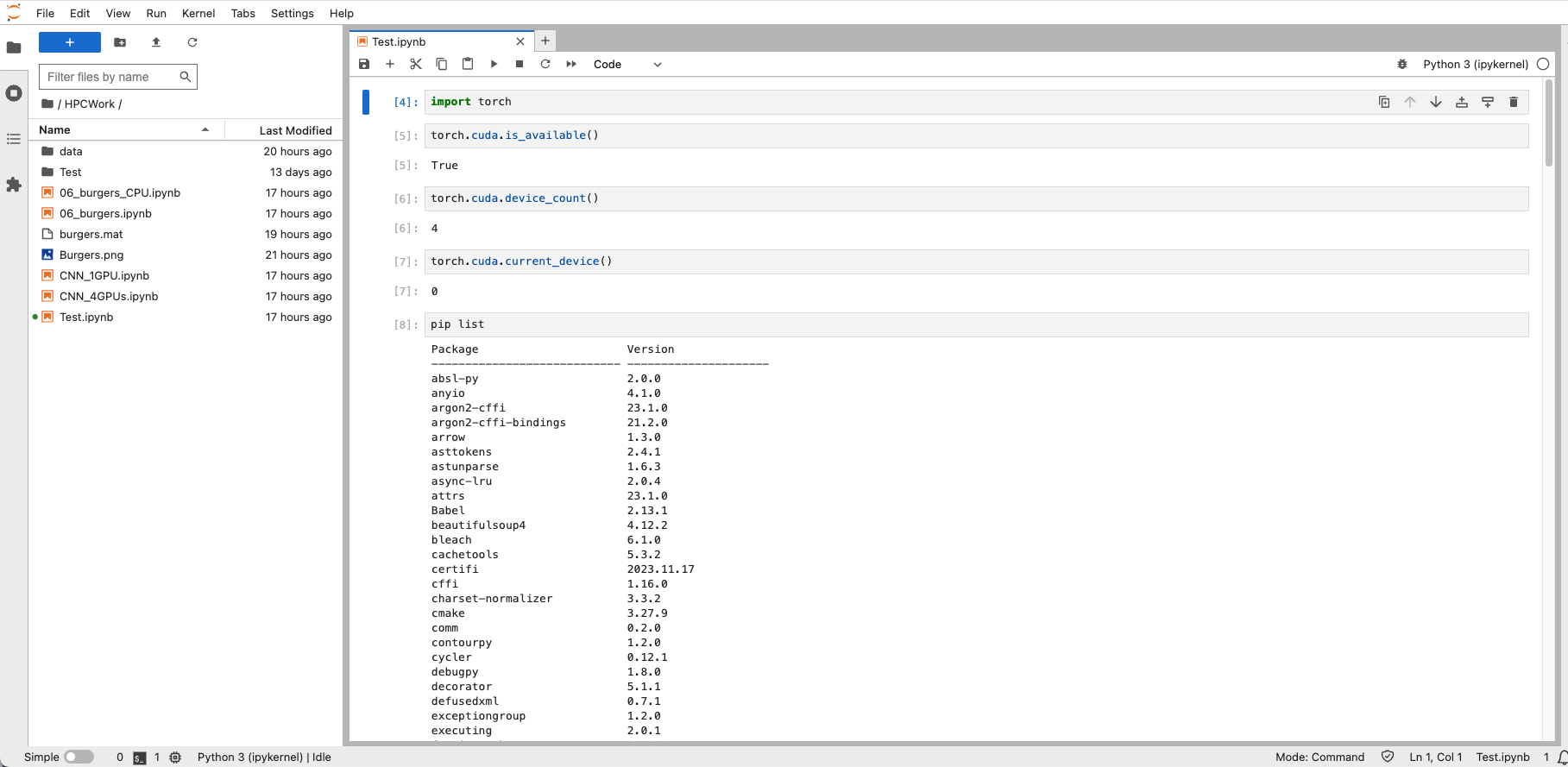
-
To install a Python package, simply type
!pip3 install <Python Package Name>.
Example Notebooks
Examples of Jupyter Notebooks Available via DesignSafe
-
PRJ-1695 | Probabilistic Seismic Hazard Analysis for the Sliding Displacement of Rigid Sliding Masses
-
Key function: Cloud-based analysis that uses external data provided by an API.
-
This workflow is about probabilistic seismic slope analysis
-
Computes slope displacement hazard curve with given information about slope and earthquake ground motion hazard
-
Uses API to directly import ground motion hazard information from USGS hazard website
-
Outputs the numeric results of the displacement hazard as csv file
-
-
PRJ-2889 | Earthquake Time Series from Events in Texas, Oklahoma, and Kansas
-
Key function: Exporting selected ground motion time series from dataset
-
This workbook is about providing a user with the ground motion data (maximum limit of 1,000 at once) available from the published data on Designsafe.
-
Receives search criteria (ranges of magnitude and distance) from a user and produces a compressed file containing all the time series of selected motion in user’s directory, Data Depot on Designsafe.
-
-
PRJ-2074 | NHERI Debris Impact Experiments Jupyter Notebook
-
Key function: GUI-based visualization and analysis of experiments
-
This notebook is about laboratory experiments on debris impact.
-
Presents images and videos of the experimental facility, setup, and experimental program through graphical user interface (GUI).
-
Performs filtering raw signals gathered from the experiments with selected frequency and range
-
Can easily view any result for a user’s interest using GUI.
-
-
PRJ-2259 | Next Generation Liquefaction (NGL) Partner Dataset Cone Penetration Test (CPT) Viewer
-
Key function: GUI-based Visualization on experimental data
-
This notebook is to visualize geotechnical field experiments (CPT).
-
Bring CPT test results located in SQL database at DesignSafe and plot the results as a function of depth and their probabilistic distributions.
-
Can easily view the results that a user wants through graphical user interface (GUI).
-
-
PRJ-2363 | Soil-Foundation-Structure Interaction Effects on the Cyclic Failure Potential of Silts and Clays
-
Key function: Post-processing of experimental data
-
This notebook is post-processing experimental data with visualization.
-
Import experimental data and process the raw data with sensors’ characteristics and filter.
-
A user can interactively view the processed experimental data
-
-
PRJ-1942 | NGA-East Geotechnical Working Group Seismic Site Response Simulation Database
-
Key function: Querying NoSQL database of numerical simulations
-
This notebook is to provide results of numerical simulations by interfacing with NoSQL database.
-
Jupyter Notebooks for Civil Engineering Courses
Directory Name: Demo
The notebooks available in this directory perform numerical integration for ordinary differential equation in engineering and science
- CentralDifference.ipynb
- Newmark_gm.ipynb: for linear elastic
- Newmark_nonlinear.ipynb: for nonlinear elastic
- reccurrenceFormulation_Equations.ipynb,
- reccurrenceFormulation_Matrix.ipynb
Directory Name: PythonSetup
SetupPythonNotebook.ipynb: Guideline on how to setup and use Jupyter notebooks on local machine across several types of operating system (Windows, Linux, and Mac) as well as in DesignSafe workspace.
The below notebooks describe how to visualize numerical results using python.
- Subplots_and_legends.ipynb
- Plot_example.ipynb
- Basic_plotting.ipynb
There are two examples for improved speed of for-loops by interfacing with C and Fortran. There is a description on how to install each package.
- Cython_fast_loops.ipynb
- Cython: a superset of the Python language that additionally supports calling C functions and declaring C types on variables and class attributes.
- Fortran_fast_loops.ipynb
- *Fortran-magic: similar to cython that allows for using Fortran language in python script for fast loop control.
Python enables one to write texts and equations in latex format for teaching purpose and provides a graphical user interface with which one can readily see the results by changing the input parameters.
-
StressRotation.ipynb: Provides a graphical user interface of Mohr Circle plot in engineering mechanics that one can see the result by changing input parameters.
-
TerzaghiPlotting.ipynb: Shows a mathematical expression in latex format and plots the solution of the partial differential equation.
-
TerzaghisTheory.ipynb: Describes Terzaghi’s theory of consolidation in soil mechanics along with markdown cell that allows for typing words and latex format. (In general term, jupyter notebook allows us to write texts for engineering and science problems like writing on white board)
Directory Name: Notebooks
Solves the mathematical equations (differential equations) through numerical analysis such as finite element or finite difference methods.
-
Stiffness_method.ipynb: linear algebra solution to get displacement (Ku=F)
-
Shape_function.ipynb: Creating Lagrange polynomials
-
Elastic_bar_linear_fem.ipynb: One dimensional truss analysis of linear elastic finite element method
-
fdm_seepage_dam.ipynb: finite difference method for numerical integration
- University of Washington (Workflow, Graduate Level Course)
Directory Name: freeFieldEffectiveJupyter
- This notebook runs OpenSees, one of the applications available from workspace on Designsafe, for a model of one-dimensional site response using the PDMY constitutive model.
Directory Name: freeFieldJupyterPM4Sand
- This notebook runs OpenSees, one of the applications available from workspace on Designsafe, for a model of one-dimensional site response using the PM4Sand constitutive model.
Publishing Notebooks
More and more researchers are publishing projects that contain Jupyter Notebooks as part of their data. They can be used to provide sample queries on the published data as well as providing digital data reports.
As you plan for publishing a Jupyter Notebook, please consider the following issues:
-
The DesignSafe publication process involves copying the contents of your project at the time of publication to a read only space within the Published projects section of the Data Depot (i.e., this directory can be accessed at NHERI-Published in JupyterHub). Any future user of your notebook will access it in the read only Published projects section. Therefore, any local path you are using while developing your notebook that is accessing a file from a private space (e.g., "MyData", "MyProjects") will need to be replaced by an absolute path to the published project.
Consider this example: you are developing a notebook in PRJ-0000 located in your "MyProjects" directory and you are reading a csv file living in this project at this path:
/home/jupyter/MyProjects/PRJ-0000/Foo.csvBefore publishing the notebook, you must change the path to this csv file to:
/home/jupyter/NHERI-Published/PRJ-0000/Foo.csv -
The published area is a read-only space. In the published section, users can run notebooks, but the notebook is not allowed to write any file to this location. If the notebook needs to write a file, you as the author of the notebook should make sure the notebook is robust to write the file in each user directory. Here is an example of a published notebook that writes files to user directories. Furthermore, since the published space is read-only, if a user wants to revise, enhance or edit the published notebook they will have to copy the notebook to their mydata and continue working on the copied version of the notebook located in their mydata. To ensure that users understand these limitations, we require a readme file be published within the project that explains how future users can run and take advantage of the Jupyter Notebook.
-
Jupyter Notebooks rely on packages that are used to develop them (e.g., numpy, geopandas, ipywidgets, CartoPy, Scikit-Learn). For preservation purposes, it is important to publish a requirement file including a list of all packages and their versions along with the notebook as a metadata file.